結構化串流程式設計指南
- 概觀
- 快速範例
- 程式設計模型
- 使用資料集和資料框的 API
- 非同步進度追蹤
- 連續處理
- 其他資訊
- 遷移指南
概觀
結構化串流處理是一個可擴充且具有容錯能力的串流處理引擎,建構在 Spark SQL 引擎之上。您可以用與在靜態資料上表達批次運算相同的方式來表達您的串流運算。Spark SQL 引擎會負責以遞增且連續的方式執行運算,並在串流資料持續抵達時更新最終結果。您可以在 Scala、Java、Python 或 R 中使用 資料集/資料框 API 來表達串流聚合、事件時間視窗、串流到批次的聯結等。運算會在同一個最佳化的 Spark SQL 引擎上執行。最後,系統會透過檢查點和寫入前記錄確保端對端完全一次的容錯保證。簡而言之,結構化串流處理提供快速、可擴充、具有容錯能力的端對端完全一次串流處理,而使用者無需考量串流處理。
在內部,預設情況下,結構化串流查詢會使用微批次處理引擎來處理,它將資料串流處理成一系列的小批次工作,進而達成低至 100 毫秒的端對端延遲和完全一次的容錯保證。然而,自 Spark 2.3 起,我們引進了一種稱為連續處理的新低延遲處理模式,它可以在至少一次的保證下達成低至 1 毫秒的端對端延遲。在不變更查詢中的資料集/資料框操作的情況下,您將能夠根據應用程式需求選擇模式。
在本指南中,我們將引導您了解程式設計模型和 API。我們將主要使用預設的微批次處理模型來解釋概念,然後 稍後 再討論連續處理模型。首先,讓我們從一個結構化串流查詢的簡單範例開始 - 串流字數計算。
快速範例
假設您想要維護從監聽 TCP socket 的資料伺服器接收的文字資料的執行中字數統計。讓我們看看如何使用結構化串流來表達這一點。您可以在 Scala/Java/Python/R 中看到完整程式碼。如果您 下載 Spark,您可以直接 執行範例。無論如何,讓我們逐步瞭解範例,並了解其運作方式。首先,我們必須匯入必要的類別,並建立一個本機 SparkSession,這是所有與 Spark 相關功能的起點。
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
spark = SparkSession \
.builder \
.appName("StructuredNetworkWordCount") \
.getOrCreate()import org.apache.spark.sql.functions._
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder
.appName("StructuredNetworkWordCount")
.getOrCreate()
import spark.implicits._import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.sql.*;
import org.apache.spark.sql.streaming.StreamingQuery;
import java.util.Arrays;
import java.util.Iterator;
SparkSession spark = SparkSession
.builder()
.appName("JavaStructuredNetworkWordCount")
.getOrCreate();sparkR.session(appName = "StructuredNetworkWordCount")接下來,讓我們建立一個串流資料框,表示從監聽 localhost:9999 的伺服器接收的文字資料,並轉換資料框以計算字數統計。
# Create DataFrame representing the stream of input lines from connection to localhost:9999
lines = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.load()
# Split the lines into words
words = lines.select(
explode(
split(lines.value, " ")
).alias("word")
)
# Generate running word count
wordCounts = words.groupBy("word").count()這個 lines 資料框表示包含串流文字資料的無界表。此表包含一個名為「value」的字串欄位,串流文字資料中的每一行都會變成表中的一列。請注意,由於我們只是在設定轉換,尚未開始轉換,因此目前不會接收任何資料。接下來,我們使用了兩個內建 SQL 函數 - split 和 explode,將每一行拆分為多列,每一列包含一個字詞。此外,我們使用函數 alias 將新欄位命名為「word」。最後,我們透過群組資料集中的唯一值並計算它們,定義了 wordCounts 資料框。請注意,這是一個串流資料框,表示串流的執行中字數統計。
// Create DataFrame representing the stream of input lines from connection to localhost:9999
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
// Split the lines into words
val words = lines.as[String].flatMap(_.split(" "))
// Generate running word count
val wordCounts = words.groupBy("value").count()這個 lines DataFrame 代表一個包含串流文字資料的無界表。這個表格包含一欄名為「value」的字串,串流文字資料中的每一行都成為表格中的一列。請注意,由於我們只是在設定轉換,尚未開始,因此目前並未接收任何資料。接下來,我們使用 .as[String] 將 DataFrame 轉換為字串的 Dataset,以便我們可以套用 flatMap 操作,將每一行分割成多個字詞。結果的 words Dataset 包含所有字詞。最後,我們透過將 Dataset 中的唯一值分組並計算它們,定義了 wordCounts DataFrame。請注意,這是一個串流 DataFrame,代表串流的執行中字詞計數。
// Create DataFrame representing the stream of input lines from connection to localhost:9999
Dataset<Row> lines = spark
.readStream()
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load();
// Split the lines into words
Dataset<String> words = lines
.as(Encoders.STRING())
.flatMap((FlatMapFunction<String, String>) x -> Arrays.asList(x.split(" ")).iterator(), Encoders.STRING());
// Generate running word count
Dataset<Row> wordCounts = words.groupBy("value").count();這個 lines DataFrame 代表一個包含串流文字資料的無界表。這個表格包含一欄名為「value」的字串,串流文字資料中的每一行都成為表格中的一列。請注意,由於我們只是在設定轉換,尚未開始,因此目前並未接收任何資料。接下來,我們使用 .as(Encoders.STRING()) 將 DataFrame 轉換為字串的 Dataset,以便我們可以套用 flatMap 操作,將每一行分割成多個字詞。結果的 words Dataset 包含所有字詞。最後,我們透過將 Dataset 中的唯一值分組並計算它們,定義了 wordCounts DataFrame。請注意,這是一個串流 DataFrame,代表串流的執行中字詞計數。
# Create DataFrame representing the stream of input lines from connection to localhost:9999
lines <- read.stream("socket", host = "localhost", port = 9999)
# Split the lines into words
words <- selectExpr(lines, "explode(split(value, ' ')) as word")
# Generate running word count
wordCounts <- count(group_by(words, "word"))這個 lines SparkDataFrame 代表一個包含串流文字資料的無界表。這個表格包含一欄名為「value」的字串,串流文字資料中的每一行都成為表格中的一列。請注意,由於我們只是在設定轉換,尚未開始,因此目前並未接收任何資料。接下來,我們有一個包含兩個 SQL 函數(split 和 explode)的 SQL 表達式,用於將每一行分割成多列,每列包含一個字詞。此外,我們將新欄位命名為「word」。最後,我們透過將 SparkDataFrame 中的唯一值分組並計算它們,定義了 wordCounts SparkDataFrame。請注意,這是一個串流 SparkDataFrame,代表串流的執行中字詞計數。
我們現在已在串流資料上設定查詢。剩下的就是實際開始接收資料並計算計數。為執行此操作,我們設定它在每次更新時將完整的計數組(由 outputMode("complete") 指定)印出至主控台。然後使用 start() 開始串流運算。
# Start running the query that prints the running counts to the console
query = wordCounts \
.writeStream \
.outputMode("complete") \
.format("console") \
.start()
query.awaitTermination()// Start running the query that prints the running counts to the console
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()// Start running the query that prints the running counts to the console
StreamingQuery query = wordCounts.writeStream()
.outputMode("complete")
.format("console")
.start();
query.awaitTermination();# Start running the query that prints the running counts to the console
query <- write.stream(wordCounts, "console", outputMode = "complete")
awaitTermination(query)執行此程式碼後,串流運算將在背景中開始。 query 物件是對該主動串流查詢的控制,我們已決定使用 awaitTermination() 等待查詢終止,以防止在查詢主動時退出程序。
若要實際執行此範例程式碼,您可以自行在 Spark 應用程式 中編譯程式碼,或在下載 Spark 後,只要 執行範例 即可。我們示範後者。您首先需要使用以下指令,以資料伺服器身分執行 Netcat(在大部分類 Unix 系統中找到的小型工具)
$ nc -lk 9999
然後,在不同的終端機中,您可以使用以下指令開始範例
$ ./bin/spark-submit examples/src/main/python/sql/streaming/structured_network_wordcount.py localhost 9999$ ./bin/run-example org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount localhost 9999$ ./bin/run-example org.apache.spark.examples.sql.streaming.JavaStructuredNetworkWordCount localhost 9999$ ./bin/spark-submit examples/src/main/r/streaming/structured_network_wordcount.R localhost 9999然後,在執行 netcat 伺服器的終端機中輸入的任何行都會被計數,並每秒印在螢幕上。它看起來會像以下內容。
|
|
程式設計模型
結構化串流中的關鍵概念是將即時資料串流視為持續追加的表格。這會產生一個新的串流處理模型,與批次處理模型非常類似。您會將串流運算表示為靜態表格上的標準批次式查詢,而 Spark 會在無界輸入表格上將其執行為增量查詢。讓我們更詳細地了解此模型。
基本概念
將輸入資料串流視為「輸入表格」。串流中抵達的每個資料項目就像新增到輸入表格的新列。

對輸入的查詢會產生「結果表格」。每一個觸發間隔(例如,每 1 秒),就會有新列新增到輸入表格,最終會更新結果表格。每當結果表格更新時,我們就會希望將變更的結果列寫入外部接收器。
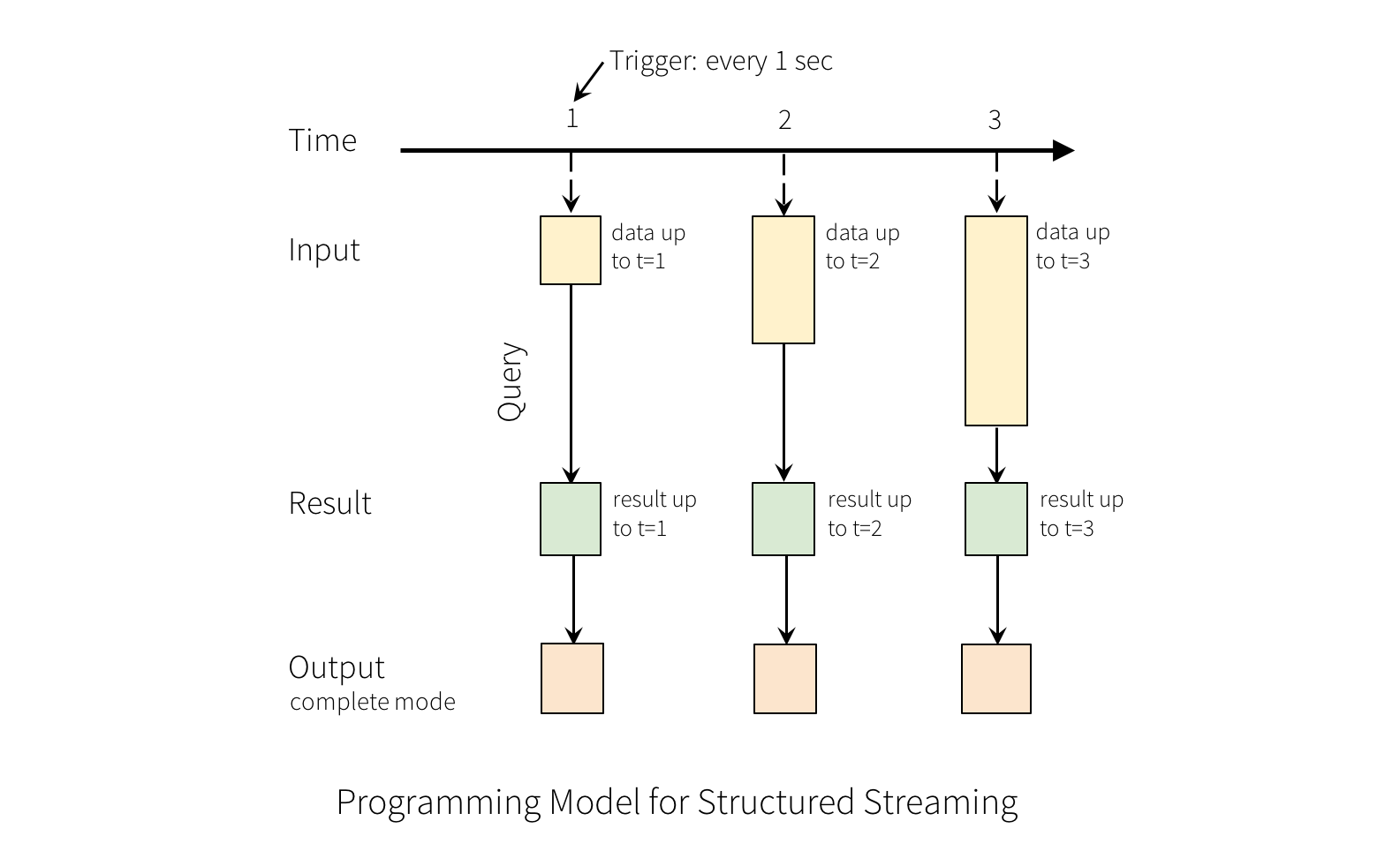
「輸出」定義為寫入外部儲存的內容。輸出可以在不同的模式中定義
-
完整模式 - 整個已更新的結果表格將寫入外部儲存。由儲存連接器決定如何處理整個表格的寫入。
-
追加模式 - 僅自上次觸發後新增至結果表的列會寫入外部儲存體。這僅適用於預期結果表中現有列不會變更的查詢。
-
更新模式 - 僅自上次觸發後在結果表中更新的列會寫入外部儲存體(自 Spark 2.1.1 起提供)。請注意,這與完整模式不同,因為此模式僅輸出自上次觸發後已變更的列。如果查詢不包含聚合,則它將等同於追加模式。
請注意,每種模式都適用於特定類型的查詢。這將在後續詳細說明。
為了說明此模型的使用方式,讓我們了解上述快速範例中的模型。第一個lines DataFrame 是輸入表格,而最後一個wordCounts DataFrame 是結果表格。請注意,針對串流lines DataFrame 以產生wordCounts 的查詢與靜態 DataFrame 的查詢完全相同。然而,當此查詢開始時,Spark 會持續檢查來自 socket 連線的新資料。如果有新資料,Spark 會執行「增量」查詢,將先前的執行計數與新資料結合,以計算更新的計數,如下所示。
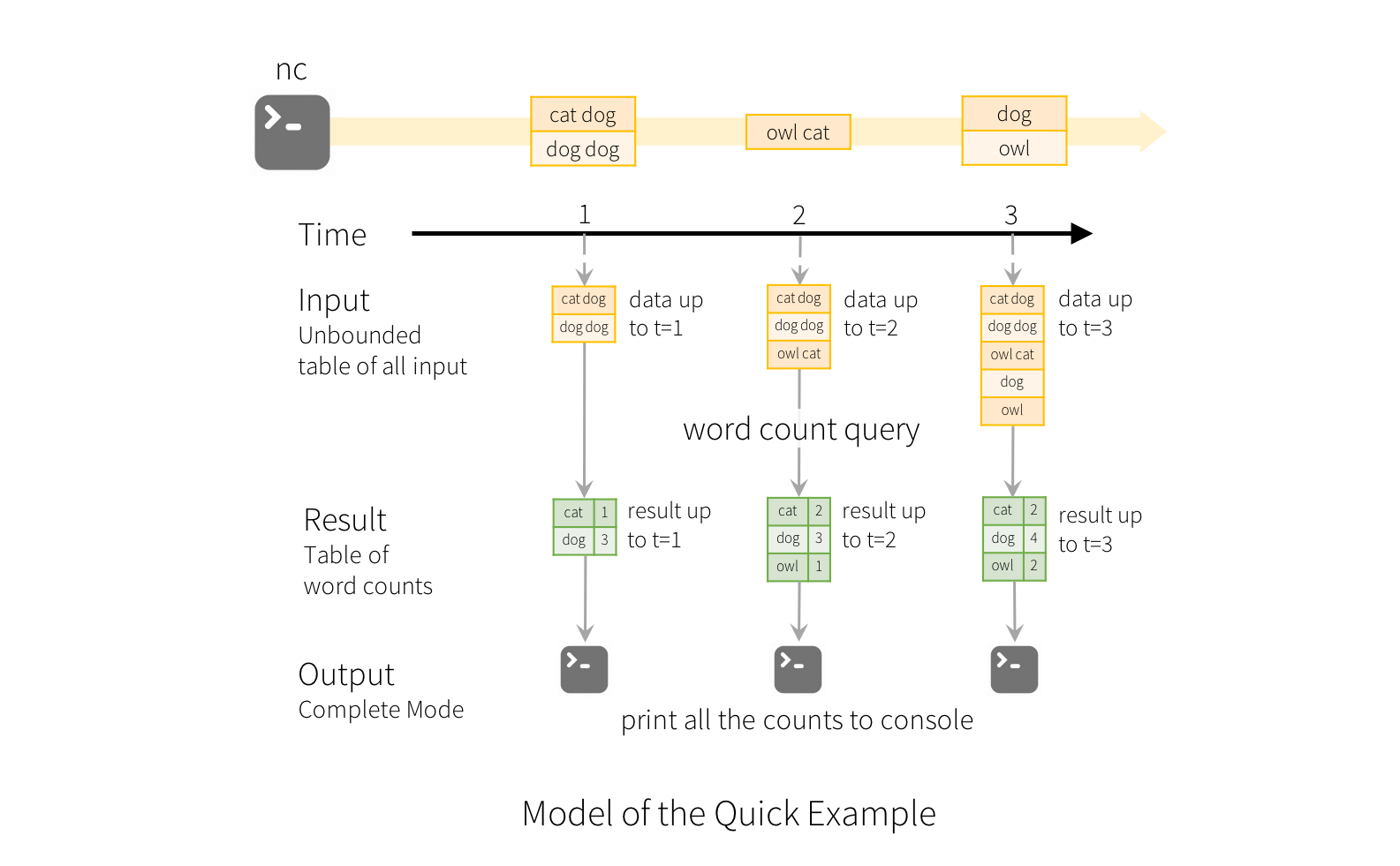
請注意,結構化串流不會實體化整個表格。它會從串流資料來源讀取最新可用的資料,以增量方式處理資料以更新結果,然後捨棄來源資料。它僅保留更新結果所需的最小中間狀態資料(例如先前範例中的中間計數)。
此模型與許多其他串流處理引擎有顯著的不同。許多串流系統要求使用者自行維護執行中的聚合,因此必須考量容錯能力和資料一致性(至少一次、最多一次或完全一次)。在此模型中,Spark 負責在有新資料時更新結果表,因此使用者不必考慮這一點。舉例來說,讓我們看看此模型如何處理基於事件時間的處理和延遲到達的資料。
處理事件時間和延遲資料
事件時間是嵌入在資料本身的時間。對於許多應用程式,您可能想要使用此事件時間。例如,如果您想要取得 IoT 裝置每分鐘產生的事件數,那麼您可能想要使用資料產生時的時間(也就是資料中的事件時間),而不是 Spark 收到這些資料的時間。此事件時間在此模型中表達得非常自然,來自裝置的每個事件都是表格中的列,而事件時間是列中的欄位值。這允許基於視窗的聚合(例如每分鐘的事件數)僅是事件時間欄位上的特殊類型的群組和聚合,每個時間視窗都是一個群組,每個列可以屬於多個視窗/群組。因此,此類基於事件時間視窗的聚合查詢可以在靜態資料集(例如來自收集的裝置事件記錄檔)和資料串流上一致地定義,讓使用者的生活更輕鬆。
此外,此模型自然會處理根據其事件時間比預期晚到的資料。由於 Spark 會更新結果表格,因此它可以完全控制在有延遲資料時更新舊的聚合,以及清除舊的聚合以限制中間狀態資料的大小。自 Spark 2.1 以來,我們支援浮水印,允許使用者指定延遲資料的閾值,並允許引擎相應地清除舊的狀態。這些會在視窗操作區段中稍後更詳細地說明。
容錯語意
提供端對端完全一次語意是結構化串流設計背後的主要目標之一。為了達成此目標,我們設計了結構化串流來源、接收器和執行引擎,以可靠地追蹤處理的精確進度,以便它可以透過重新啟動和/或重新處理來處理任何類型的失敗。假設每個串流來源都有偏移量(類似於 Kafka 偏移量或 Kinesis 順序號碼)來追蹤串流中的讀取位置。引擎使用檢查點和寫入先決記錄來記錄在每個觸發器中處理的資料的偏移量範圍。串流接收器設計為在處理重新處理時具有冪等性。結構化串流結合可重播來源和冪等接收器,可以在任何失敗下確保端對端完全一次語意。
使用資料集和資料框的 API
自 Spark 2.0 起,DataFrames 和 Datasets 可表示靜態、有界資料,以及串流、無界資料。類似於靜態 Datasets/DataFrames,您可以使用常見的進入點 SparkSession (Scala/Java/Python/R 文件) 從串流來源建立串流 DataFrames/Datasets,並對其套用與靜態 DataFrames/Datasets 相同的運算。如果您不熟悉 Datasets/DataFrames,強烈建議您使用 DataFrame/Dataset 程式設計指南 來熟悉它們。
建立串流資料框和串流資料集
串流 DataFrames 可透過 DataStreamReader 介面 (Scala/Java/Python 文件) 建立,此介面由 SparkSession.readStream() 傳回。在 R 中,使用 read.stream() 方法。類似於建立靜態 DataFrame 的讀取介面,您可以指定來源的詳細資料,例如資料格式、架構、選項等。
輸入來源
有幾個內建來源。
- 檔案來源 - 將目錄中寫入的檔案讀取為資料串流。檔案將依檔案修改時間的順序處理。如果設定
latestFirst,順序將會反轉。支援的檔案格式為文字、CSV、JSON、ORC、Parquet。請參閱 DataStreamReader 介面的文件,以取得最新清單,以及每個檔案格式支援的選項。請注意,檔案必須以原子方式放置在指定的目錄中,在大部分檔案系統中,這可透過檔案移動運算來達成。 -
Kafka 來源 - 從 Kafka 讀取資料。它與 Kafka 仲介版本 0.10.0 或更高版本相容。請參閱 Kafka 整合指南 以取得更多詳細資料。
-
Socket 來源 (用於測試) - 從 Socket 連線讀取 UTF8 文字資料。監聽伺服器 Socket 位於驅動程式中。請注意,這應僅用於測試,因為這不提供端對端的容錯保證。
-
速率來源 (用於測試) - 以每秒指定列數產生資料,每一個輸出列包含一個
timestamp和value。其中timestamp是Timestamp類型,包含訊息傳送時間,而value是Long類型,包含訊息計數,從 0 開始作為第一列。此來源用於測試和基準測試。 - 每微批次速率來源 (用於測試) - 以每微批次指定列數產生資料,每一個輸出列包含一個
timestamp和value。其中timestamp是Timestamp類型,包含訊息傳送時間,而value是Long類型,包含訊息計數,從 0 開始作為第一列。與rate資料來源不同,此資料來源提供每微批次一致的輸入列集合,不論查詢執行 (觸發器組態、查詢落後等) 如何,例如,批次 0 將產生 0~999,批次 1 將產生 1000~1999,以此類推。產生的時間也適用相同的規則。此來源用於測試和基準測試。
有些來源並非容錯,因為它們無法保證在發生故障後,可以使用檢查點偏移重播資料。請參閱較早關於 容錯語意的章節。以下是 Spark 中所有來源的詳細資訊。
| 來源 | 選項 | 容錯 | 注意事項 |
|---|---|---|---|
| 檔案來源 |
path:輸入目錄路徑,所有檔案格式共用。
maxFilesPerTrigger:每個觸發器中要考量的最大新檔案數目(預設:無最大值)
latestFirst:是否先處理最新的新檔案,在有大量積壓檔案時很有用(預設:false)
fileNameOnly:是否只根據檔名,而不是完整路徑來檢查新檔案(預設:false)。將此設定為 `true`,下列檔案會被視為同一個檔案,因為它們的檔名「dataset.txt」相同
"file:///dataset.txt" "s3://a/dataset.txt" "s3n://a/b/dataset.txt" "s3a://a/b/c/dataset.txt" maxFileAge:此目錄中檔案的最大年齡,超過此年齡後將被忽略。在第一批次中,所有檔案都將被視為有效。如果將 latestFirst 設定為 `true`,並設定 maxFilesPerTrigger,則此參數將被忽略,因為有效且應處理的舊檔案可能會被忽略。最大年齡是根據最新檔案的時間戳指定,而不是根據目前系統的時間戳。(預設:1 週)
cleanSource:處理完畢後清除已完成檔案的選項。可用的選項為「封存」、「刪除」、「關閉」。如果未提供選項,預設值為「關閉」。 如果提供「封存」,則也必須提供其他選項 sourceArchiveDir。sourceArchiveDir 的值不得與來源模式在深度上相符(從根目錄的目錄數目),其中深度為兩條路徑的最小深度。這樣可確保封存的檔案絕不會包含為新的來源檔案。例如,假設您提供 '/hello?/spark/*' 作為來源模式,則 '/hello1/spark/archive/dir' 不能用作「sourceArchiveDir」的值,因為 '/hello?/spark/*' 和 '/hello1/spark/archive' 將會匹配。'/hello1/spark' 也不能用作「sourceArchiveDir」的值,因為 '/hello?/spark' 和 '/hello1/spark' 將會匹配。'/archived/here' 會是 OK 的,因為它不會匹配。 Spark 會移動來源檔案,並尊重其自己的路徑。例如,如果來源檔案的路徑是 /a/b/dataset.txt,而封存目錄的路徑是 /archived/here,則檔案會移動到 /archived/here/a/b/dataset.txt。注意:封存(透過移動)或刪除已完成檔案都會在每個微批次中引入負擔(變慢,即使是在不同的執行緒中發生),因此您需要在啟用此選項之前了解檔案系統中每個操作的成本。另一方面,啟用此選項會減少列出來源檔案的成本,而這可能是一個昂貴的操作。 已完成檔案清理程式中使用的執行緒數目可以使用 spark.sql.streaming.fileSource.cleaner.numThreads(預設值:1)來設定。注意 2:在啟用此選項時,來源路徑不應從多個來源或查詢中使用。同樣地,您必須確保來源路徑與檔案串流接收器輸出目錄中的任何檔案都不匹配。 注意 3:刪除和移動動作都是盡力而為。無法刪除或移動檔案不會導致串流查詢失敗。在某些情況下,Spark 可能無法清理某些來源檔案 - 例如應用程式沒有正常關閉,有太多檔案排隊要清理。 有關特定檔案格式的選項,請參閱 DataStreamReader 中的相關方法(Scala/Java/Python/R)。例如,有關「parquet」格式選項,請參閱 DataStreamReader.parquet()。
此外,還有會影響某些檔案格式的階段設定。有關更多詳細資訊,請參閱 SQL 程式設計指南。例如,有關「parquet」,請參閱 Parquet 設定 部分。 |
是 | 支援 glob 路徑,但不支援多個以逗號分隔的路徑/glob。 |
| Socket 來源 |
host:要連線的主機,必須指定port:要連線的埠,必須指定
|
否 | |
| Rate 來源 |
rowsPerSecond(例如 100,預設值:1):每秒應產生多少列。rampUpTime(例如 5 秒,預設:0 秒):在產生速度變為 rowsPerSecond 之前,要增加多長的時間。使用比秒更精細的粒度將會被截斷為整數秒。 numPartitions(例如 10,預設:Spark 的預設並行性):產生列的分割區號碼。 來源會盡力達到 rowsPerSecond,但查詢可能會受到資源限制,而 numPartitions 可以調整以協助達到所需的速率。
|
是 | |
| 每個微批次來源的速率(格式:rate-micro-batch) |
rowsPerBatch(例如 100):每個微批次應產生多少列。numPartitions(例如 10,預設:Spark 的預設並行性):產生列的分割區號碼。 startTimestamp(例如 1000,預設:0):產生時間的起始值。 advanceMillisPerBatch(例如 1000,預設:1000):每個微批次中產生的時間進展量。 |
是 | |
| Kafka 來源 | 請參閱 Kafka 整合指南。 | 是 | |
以下是一些範例。
spark = SparkSession. ...
# Read text from socket
socketDF = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.load()
socketDF.isStreaming() # Returns True for DataFrames that have streaming sources
socketDF.printSchema()
# Read all the csv files written atomically in a directory
userSchema = StructType().add("name", "string").add("age", "integer")
csvDF = spark \
.readStream \
.option("sep", ";") \
.schema(userSchema) \
.csv("/path/to/directory") # Equivalent to format("csv").load("/path/to/directory")val spark: SparkSession = ...
// Read text from socket
val socketDF = spark
.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
socketDF.isStreaming // Returns True for DataFrames that have streaming sources
socketDF.printSchema
// Read all the csv files written atomically in a directory
val userSchema = new StructType().add("name", "string").add("age", "integer")
val csvDF = spark
.readStream
.option("sep", ";")
.schema(userSchema) // Specify schema of the csv files
.csv("/path/to/directory") // Equivalent to format("csv").load("/path/to/directory")SparkSession spark = ...
// Read text from socket
Dataset<Row> socketDF = spark
.readStream()
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load();
socketDF.isStreaming(); // Returns True for DataFrames that have streaming sources
socketDF.printSchema();
// Read all the csv files written atomically in a directory
StructType userSchema = new StructType().add("name", "string").add("age", "integer");
Dataset<Row> csvDF = spark
.readStream()
.option("sep", ";")
.schema(userSchema) // Specify schema of the csv files
.csv("/path/to/directory"); // Equivalent to format("csv").load("/path/to/directory")sparkR.session(...)
# Read text from socket
socketDF <- read.stream("socket", host = hostname, port = port)
isStreaming(socketDF) # Returns TRUE for SparkDataFrames that have streaming sources
printSchema(socketDF)
# Read all the csv files written atomically in a directory
schema <- structType(structField("name", "string"),
structField("age", "integer"))
csvDF <- read.stream("csv", path = "/path/to/directory", schema = schema, sep = ";")這些範例會產生未分型的串流資料框,表示資料框的架構不會在編譯時檢查,只會在提交查詢時在執行階段檢查。某些作業(例如 map、flatMap 等)需要在編譯時知道型別。若要執行這些作業,您可以使用與靜態資料框相同的方法將這些未分型的串流資料框轉換為分型的串流資料集。請參閱 SQL 程式設計指南 以取得更多詳細資訊。此外,稍後會在文件中討論更多關於支援的串流來源的詳細資訊。
自 Spark 3.1 起,您也可以使用 DataStreamReader.table() 從表格建立串流資料框。請參閱 串流表格 API 以取得更多詳細資訊。
串流資料框/資料集的架構推論和分割
預設情況下,從檔案來源進行的結構化串流需要您指定架構,而不是依賴 Spark 自動推斷。此限制可確保即使在發生故障的情況下,串流查詢也會使用一致的架構。對於臨時用例,您可以透過將 spark.sql.streaming.schemaInference 設定為 true 來重新啟用架構推斷。
當存在命名為 /key=value/ 的子目錄時,就會發生分割區偵測,而且清單會自動遞迴至這些目錄。如果這些欄位出現在使用者提供的架構中,則 Spark 會根據正在讀取的檔案路徑填入這些欄位。構成分割區配置的目錄必須在查詢開始時存在,而且必須保持靜態。例如,當 /data/year=2015/ 存在時,新增 /data/year=2016/ 是可以的,但變更分割區欄位(也就是建立目錄 /data/date=2016-04-17/)則無效。
串流資料框/資料集的運算
您可以對串流資料架構/資料集套用各種運算,從未輸入類型、類似 SQL 的運算(例如 select、where、groupBy),到輸入類型 RDD 類型的運算(例如 map、filter、flatMap)。請參閱 SQL 程式設計指南 以取得更多詳細資料。讓我們來看看幾個您可以使用的範例運算。
基本運算 - 選取、投影、聚合
大多數在資料架構/資料集上的常見運算都支援串流。在本節稍後會 討論 不支援的少數運算。
df = ... # streaming DataFrame with IOT device data with schema { device: string, deviceType: string, signal: double, time: DateType }
# Select the devices which have signal more than 10
df.select("device").where("signal > 10")
# Running count of the number of updates for each device type
df.groupBy("deviceType").count()case class DeviceData(device: String, deviceType: String, signal: Double, time: DateTime)
val df: DataFrame = ... // streaming DataFrame with IOT device data with schema { device: string, deviceType: string, signal: double, time: string }
val ds: Dataset[DeviceData] = df.as[DeviceData] // streaming Dataset with IOT device data
// Select the devices which have signal more than 10
df.select("device").where("signal > 10") // using untyped APIs
ds.filter(_.signal > 10).map(_.device) // using typed APIs
// Running count of the number of updates for each device type
df.groupBy("deviceType").count() // using untyped API
// Running average signal for each device type
import org.apache.spark.sql.expressions.scalalang.typed
ds.groupByKey(_.deviceType).agg(typed.avg(_.signal)) // using typed APIimport org.apache.spark.api.java.function.*;
import org.apache.spark.sql.*;
import org.apache.spark.sql.expressions.javalang.typed;
import org.apache.spark.sql.catalyst.encoders.ExpressionEncoder;
public class DeviceData {
private String device;
private String deviceType;
private Double signal;
private java.sql.Date time;
...
// Getter and setter methods for each field
}
Dataset<Row> df = ...; // streaming DataFrame with IOT device data with schema { device: string, type: string, signal: double, time: DateType }
Dataset<DeviceData> ds = df.as(ExpressionEncoder.javaBean(DeviceData.class)); // streaming Dataset with IOT device data
// Select the devices which have signal more than 10
df.select("device").where("signal > 10"); // using untyped APIs
ds.filter((FilterFunction<DeviceData>) value -> value.getSignal() > 10)
.map((MapFunction<DeviceData, String>) value -> value.getDevice(), Encoders.STRING());
// Running count of the number of updates for each device type
df.groupBy("deviceType").count(); // using untyped API
// Running average signal for each device type
ds.groupByKey((MapFunction<DeviceData, String>) value -> value.getDeviceType(), Encoders.STRING())
.agg(typed.avg((MapFunction<DeviceData, Double>) value -> value.getSignal()));df <- ... # streaming DataFrame with IOT device data with schema { device: string, deviceType: string, signal: double, time: DateType }
# Select the devices which have signal more than 10
select(where(df, "signal > 10"), "device")
# Running count of the number of updates for each device type
count(groupBy(df, "deviceType"))您也可以將串流資料架構/資料集註冊為暫時檢視,然後對其套用 SQL 指令。
df.createOrReplaceTempView("updates")
spark.sql("select count(*) from updates") # returns another streaming DFdf.createOrReplaceTempView("updates")
spark.sql("select count(*) from updates") // returns another streaming DFdf.createOrReplaceTempView("updates");
spark.sql("select count(*) from updates"); // returns another streaming DFcreateOrReplaceTempView(df, "updates")
sql("select count(*) from updates")請注意,您可以使用 df.isStreaming 來識別資料架構/資料集是否具有串流資料。
df.isStreaming()df.isStreamingdf.isStreaming()isStreaming(df)您可能想要檢查查詢的查詢計畫,因為 Spark 可以在針對串流資料集的 SQL 陳述句進行詮釋時插入有狀態運算。一旦有狀態運算插入查詢計畫,您可能需要根據有狀態運算的考量來檢查您的查詢(例如輸出模式、浮水印、狀態儲存大小維護等)。
事件時間的視窗運算
使用結構化串流進行滑動事件時間視窗的聚合非常容易,而且與群組聚合非常類似。在群組聚合中,會針對使用者指定的群組欄位中的每個唯一值維護聚合值(例如計數)。在視窗式聚合中,會針對事件時間落在其中的每個視窗維護聚合值。讓我們透過一個說明來了解這一點。
想像我們的 快速範例 已修改,串流現在包含行以及產生該行的時間。我們不執行詞彙計數,而是要計算 10 分鐘視窗內的詞彙,每 5 分鐘更新一次。也就是說,在 10 分鐘視窗 12:00 - 12:10、12:05 - 12:15、12:10 - 12:20 等之間接收到的詞彙計數。請注意,12:00 - 12:10 表示在 12:00 之後但 12:10 之前到達的資料。現在,考慮一個在 12:07 收到的詞彙。這個詞彙應增加對應於兩個視窗 12:00 - 12:10 和 12:05 - 12:15 的計數。因此,計數將由群組金鑰(即詞彙)和視窗(可從事件時間計算)編制索引。
結果表格看起來會像以下範例。
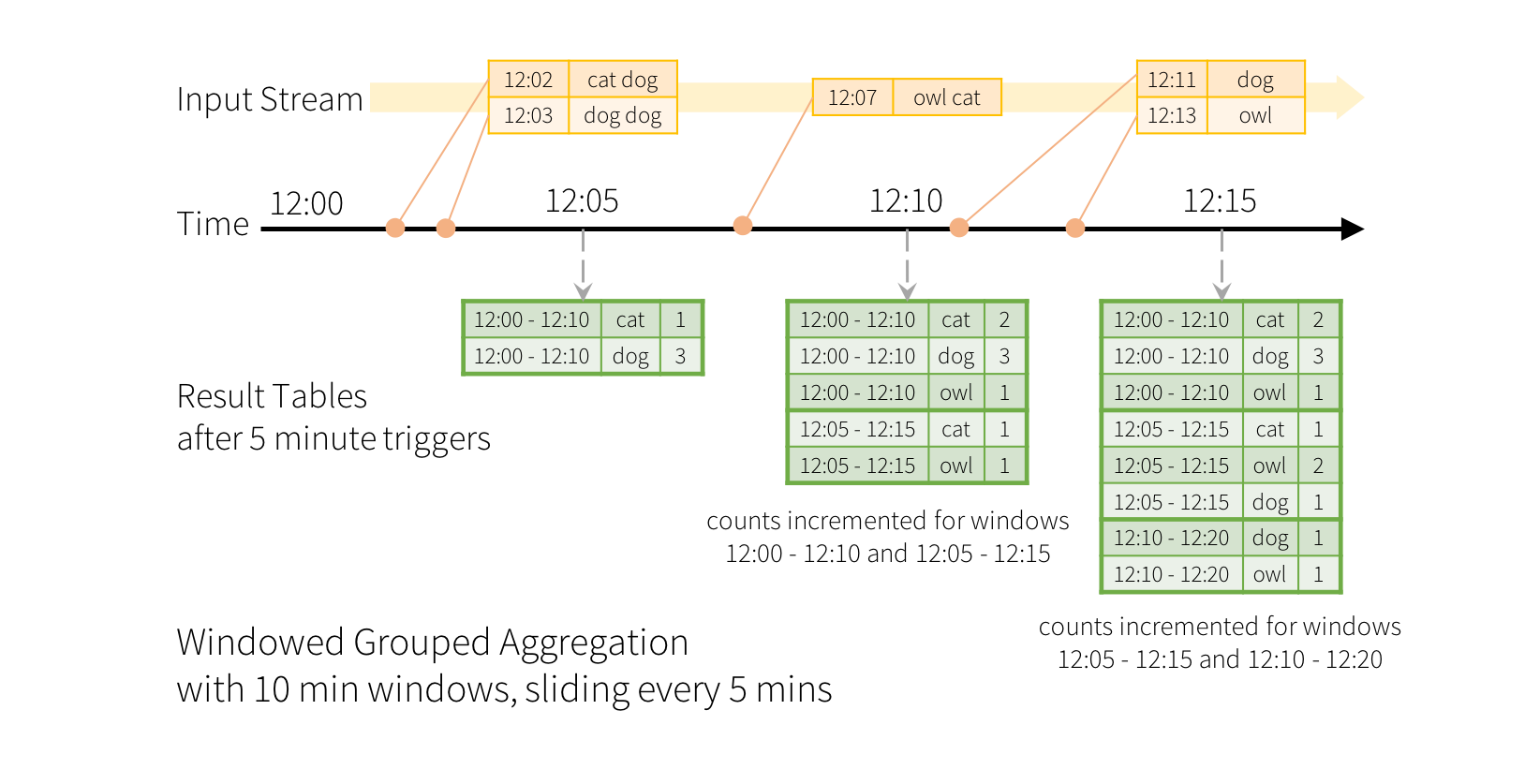
由於這個視窗化類似於群組化,在程式碼中,您可以使用 groupBy() 和 window() 運算來表達視窗化聚合。您可以在 Scala/Java/Python 中查看以下範例的完整程式碼。
words = ... # streaming DataFrame of schema { timestamp: Timestamp, word: String }
# Group the data by window and word and compute the count of each group
windowedCounts = words.groupBy(
window(words.timestamp, "10 minutes", "5 minutes"),
words.word
).count()import spark.implicits._
val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
val windowedCounts = words.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word"
).count()Dataset<Row> words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
Dataset<Row> windowedCounts = words.groupBy(
functions.window(words.col("timestamp"), "10 minutes", "5 minutes"),
words.col("word")
).count();words <- ... # streaming DataFrame of schema { timestamp: Timestamp, word: String }
# Group the data by window and word and compute the count of each group
windowedCounts <- count(
groupBy(
words,
window(words$timestamp, "10 minutes", "5 minutes"),
words$word))處理延遲資料和浮水印
現在考慮如果其中一個事件延遲到達應用程式會發生什麼事。例如,假設在 12:04 (即事件時間) 產生的詞彙可能在 12:11 被應用程式收到。應用程式應使用時間 12:04 而不是 12:11 來更新視窗 12:00 - 12:10 的舊計數。這會自然發生在我們的基於視窗的群組化中 - 結構化串流可以長時間維護部分聚合的中間狀態,以便延遲資料可以正確更新舊視窗的聚合,如下所示。
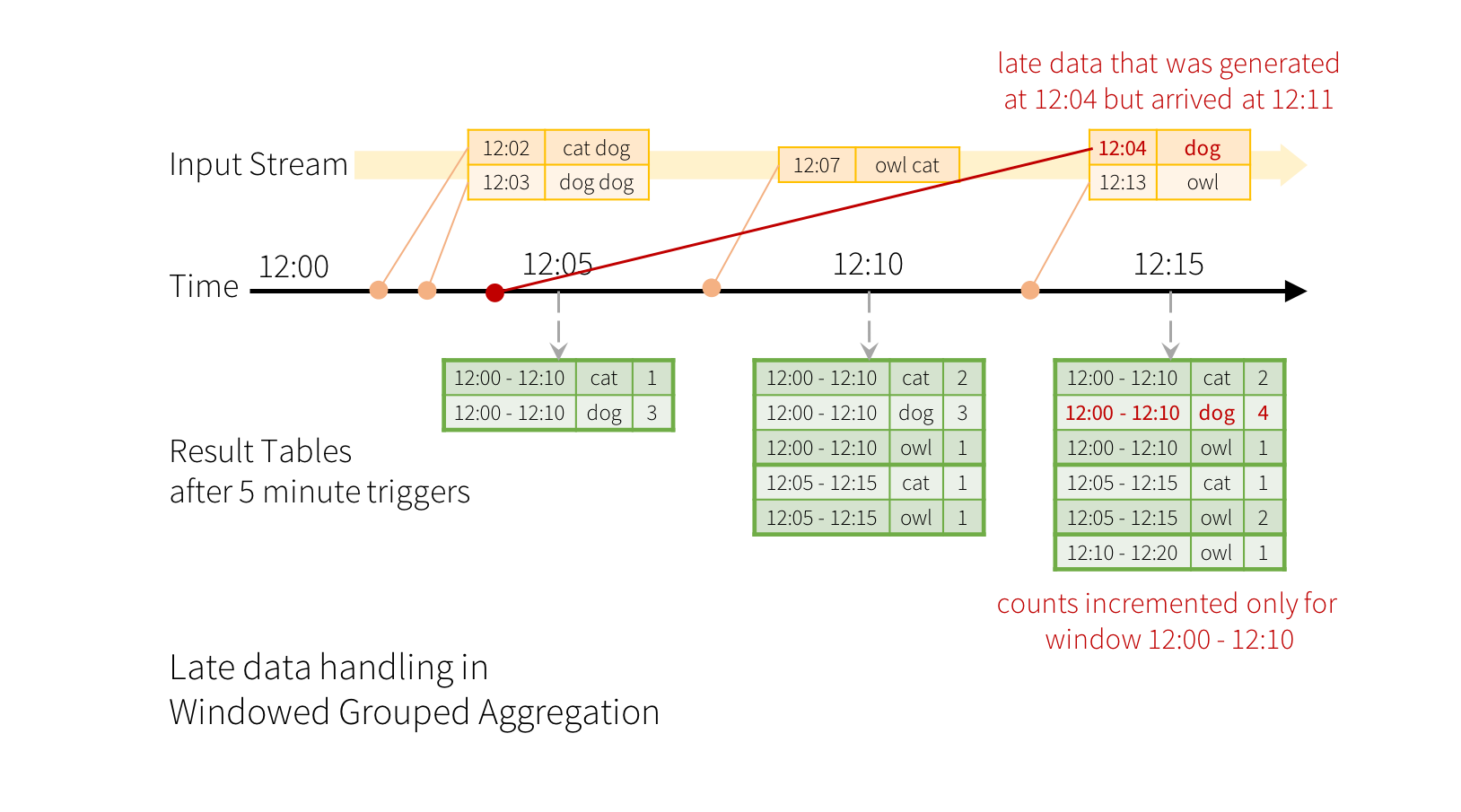
但是,要執行這個查詢數天,系統必須限制它累積的中間記憶體中狀態的數量。這表示系統需要知道何時可以從記憶體中狀態中刪除舊聚合,因為應用程式不會再收到該聚合的延遲資料。為啟用此功能,在 Spark 2.1 中,我們引入了浮水印,它讓引擎自動追蹤資料中的目前事件時間,並嘗試相應地清除舊狀態。您可以透過指定事件時間欄位和資料預計延遲多久的閾值來定義查詢的浮水印。對於在時間 T 結束的特定視窗,引擎將維護狀態並允許延遲資料更新狀態,直到 (引擎看到的最大事件時間 - 延遲閾值 > T)。換句話說,在閾值內的延遲資料將被聚合,但超過閾值的資料將開始被刪除(請參閱本節的 後續內容 以取得確切保證)。讓我們透過一個範例來了解這一點。我們可以使用 withWatermark() 輕鬆對前一個範例定義浮水印,如下所示。
words = ... # streaming DataFrame of schema { timestamp: Timestamp, word: String }
# Group the data by window and word and compute the count of each group
windowedCounts = words \
.withWatermark("timestamp", "10 minutes") \
.groupBy(
window(words.timestamp, "10 minutes", "5 minutes"),
words.word) \
.count()import spark.implicits._
val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
val windowedCounts = words
.withWatermark("timestamp", "10 minutes")
.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word")
.count()Dataset<Row> words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
Dataset<Row> windowedCounts = words
.withWatermark("timestamp", "10 minutes")
.groupBy(
window(col("timestamp"), "10 minutes", "5 minutes"),
col("word"))
.count();words <- ... # streaming DataFrame of schema { timestamp: Timestamp, word: String }
# Group the data by window and word and compute the count of each group
words <- withWatermark(words, "timestamp", "10 minutes")
windowedCounts <- count(
groupBy(
words,
window(words$timestamp, "10 minutes", "5 minutes"),
words$word))在此範例中,我們在欄位「timestamp」的值上定義查詢的浮水印,並將「10 分鐘」定義為資料允許延遲的閾值。如果這個查詢在更新輸出模式中執行(稍後在 輸出模式 部分中討論),引擎將持續更新結果表格中視窗的計數,直到視窗早於浮水印,而浮水印落後於欄位「timestamp」中的目前事件時間 10 分鐘。以下是說明。
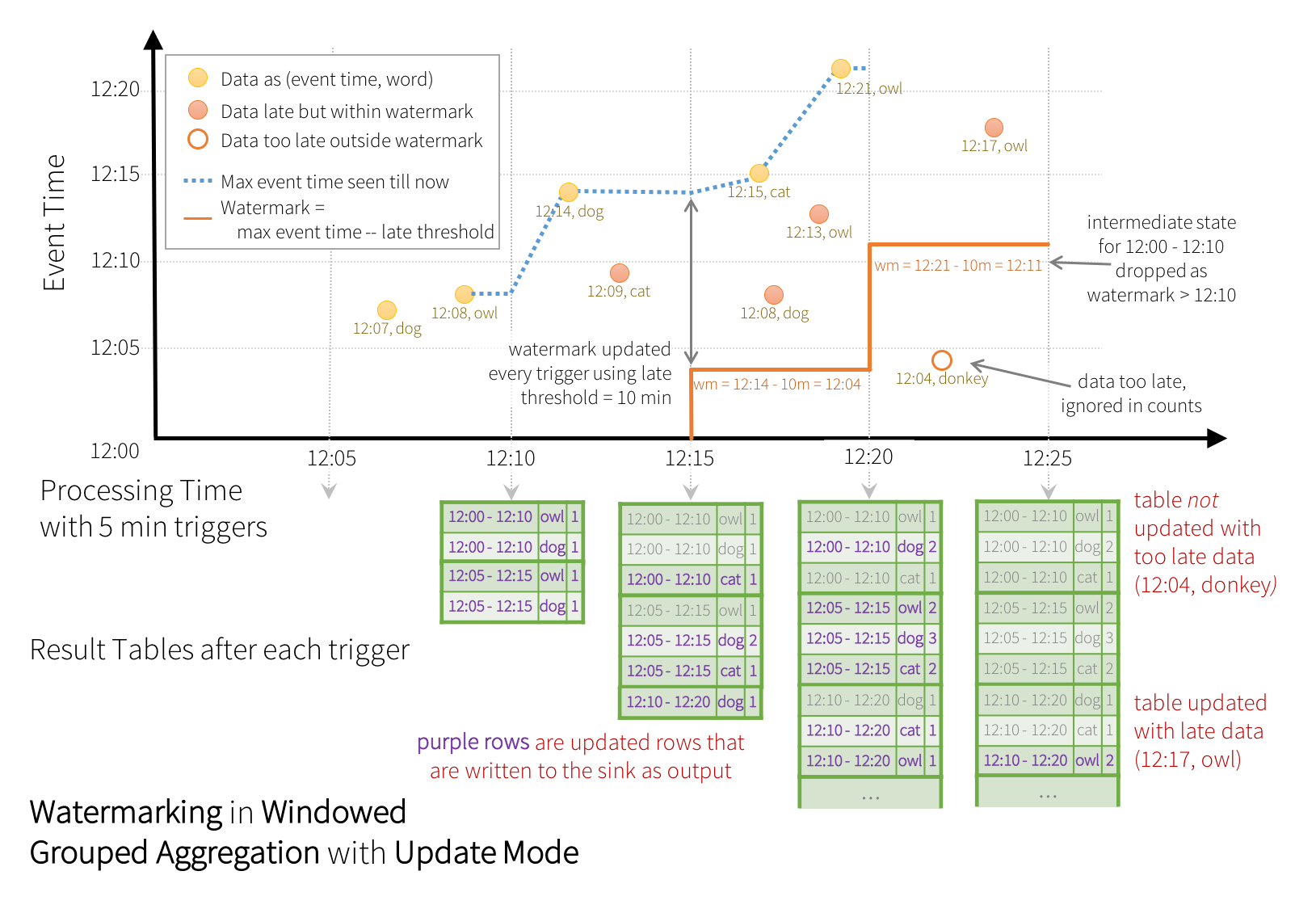
如圖所示,引擎追蹤的最大事件時間為藍色虛線,而每個觸發器開始時設定的水位標記為 (最大事件時間 - '10 分鐘'),為紅色線條。例如,當引擎觀察到資料 (12:14, dog) 時,它將下一個觸發器的水位標記設定為 12:04。這個水位標記讓引擎可以維持中間狀態額外 10 分鐘,以允許計數遲到資料。例如,資料 (12:09, cat) 是亂序且遲到的,它落在視窗 12:00 - 12:10 和 12:05 - 12:15。由於它仍領先於觸發器中的水位標記 12:04,因此引擎仍維持中間計數為狀態,並正確更新相關視窗的計數。然而,當水位標記更新為 12:11 時,視窗 (12:00 - 12:10) 的中間狀態會被清除,而所有後續資料(例如 (12:04, donkey))會被視為「太遲」,因此會被忽略。請注意,在每個觸發器之後,更新的計數(即紫色列)會根據更新模式的指示寫入儲存槽作為觸發器輸出。
有些儲存槽(例如檔案)可能不支援更新模式所需的細緻更新。為了配合這些儲存槽,我們也支援附加模式,其中只有最終計數會寫入儲存槽。如下圖所示。
請注意,對非串流資料集使用 withWatermark 是無效操作。由於水位標記不應以任何方式影響任何批次查詢,因此我們會直接忽略它。
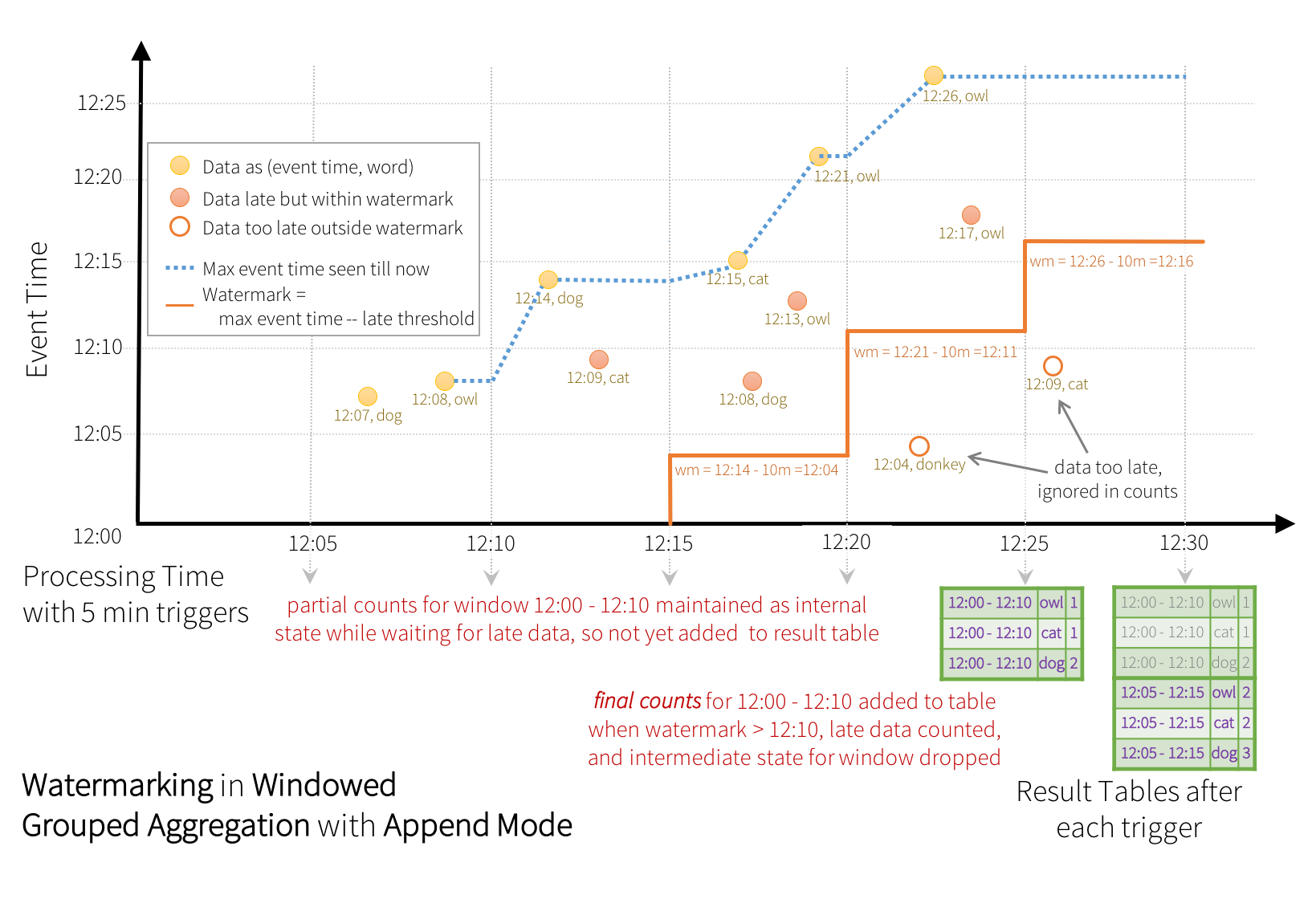
類似於先前的更新模式,引擎會為每個視窗維持中間計數。然而,部分計數不會更新至結果表格,也不會寫入儲存槽。引擎會等待「10 分鐘」讓遲到的資料進行計數,然後刪除水位標記 < 的視窗中間狀態,並將最終計數附加至結果表格/儲存槽。例如,視窗 12:00 - 12:10 的最終計數只會在水位標記更新為 12:11 之後才附加至結果表格。
時間視窗類型
Spark 支援三種類型的時間視窗:翻轉(固定)、滑動和階段。
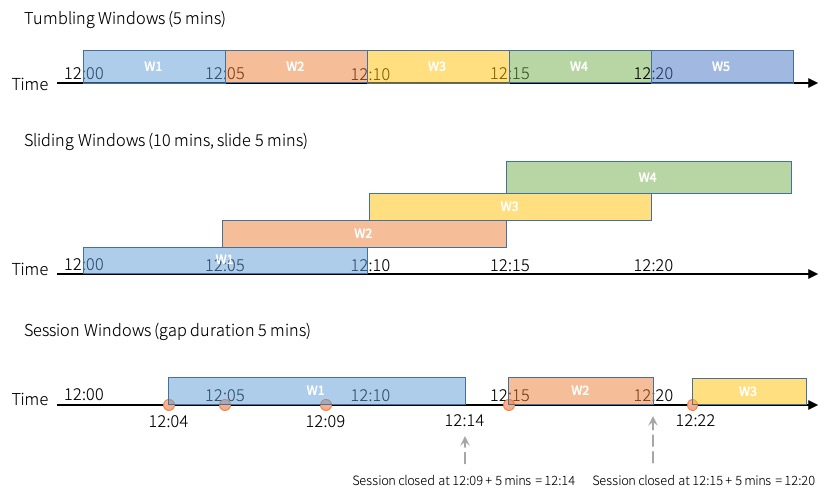
翻轉視窗是一系列固定大小、不重疊且連續的時間區間。輸入只能繫結至單一視窗。
滑動視窗與滾動視窗在「固定大小」這點上很像,但如果滑動時間小於視窗時間,視窗就會重疊,而且在這種情況下,輸入可以繫結到多個視窗。
滾動視窗和滑動視窗使用window函數,如上方的範例所述。
與前兩種類型相比,工作階段視窗有不同的特性。工作階段視窗的視窗長度大小會動態變動,視輸入而定。工作階段視窗會從輸入開始,如果在間隔時間內收到後續輸入,就會擴充自己。對於靜態間隔時間,工作階段視窗會在收到最新輸入後,在間隔時間內沒有收到輸入時關閉。
工作階段視窗使用session_window函數。函數的使用方式類似於window函數。
events = ... # streaming DataFrame of schema { timestamp: Timestamp, userId: String }
# Group the data by session window and userId, and compute the count of each group
sessionizedCounts = events \
.withWatermark("timestamp", "10 minutes") \
.groupBy(
session_window(events.timestamp, "5 minutes"),
events.userId) \
.count()import spark.implicits._
val events = ... // streaming DataFrame of schema { timestamp: Timestamp, userId: String }
// Group the data by session window and userId, and compute the count of each group
val sessionizedCounts = events
.withWatermark("timestamp", "10 minutes")
.groupBy(
session_window($"timestamp", "5 minutes"),
$"userId")
.count()Dataset<Row> events = ... // streaming DataFrame of schema { timestamp: Timestamp, userId: String }
// Group the data by session window and userId, and compute the count of each group
Dataset<Row> sessionizedCounts = events
.withWatermark("timestamp", "10 minutes")
.groupBy(
session_window(col("timestamp"), "5 minutes"),
col("userId"))
.count();我們也可以提供一個表示式,而不是靜態值,以根據輸入列動態指定間隔時間。請注意,間隔時間為負值或零的列會從聚合中濾出。
使用動態間隔時間時,工作階段視窗的關閉不再依賴於最新輸入。工作階段視窗的範圍是所有事件範圍的聯集,這些範圍是由事件開始時間和查詢執行期間評估的間隔時間決定的。
from pyspark.sql import functions as sf
events = ... # streaming DataFrame of schema { timestamp: Timestamp, userId: String }
session_window = session_window(events.timestamp, \
sf.when(events.userId == "user1", "5 seconds") \
.when(events.userId == "user2", "20 seconds").otherwise("5 minutes"))
# Group the data by session window and userId, and compute the count of each group
sessionizedCounts = events \
.withWatermark("timestamp", "10 minutes") \
.groupBy(
session_window,
events.userId) \
.count()import spark.implicits._
val events = ... // streaming DataFrame of schema { timestamp: Timestamp, userId: String }
val sessionWindow = session_window($"timestamp", when($"userId" === "user1", "5 seconds")
.when($"userId" === "user2", "20 seconds")
.otherwise("5 minutes"))
// Group the data by session window and userId, and compute the count of each group
val sessionizedCounts = events
.withWatermark("timestamp", "10 minutes")
.groupBy(
Column(sessionWindow),
$"userId")
.count()Dataset<Row> events = ... // streaming DataFrame of schema { timestamp: Timestamp, userId: String }
SessionWindow sessionWindow = session_window(col("timestamp"), when(col("userId").equalTo("user1"), "5 seconds")
.when(col("userId").equalTo("user2"), "20 seconds")
.otherwise("5 minutes"))
// Group the data by session window and userId, and compute the count of each group
Dataset<Row> sessionizedCounts = events
.withWatermark("timestamp", "10 minutes")
.groupBy(
new Column(sessionWindow),
col("userId"))
.count();請注意,在串流查詢中使用工作階段視窗時有一些限制,如下所示
- 不支援「更新模式」作為輸出模式。
- 群組金鑰中應至少有一欄除了
session_window。
對於批次查詢,支援全域視窗(群組金鑰中只有session_window)。
預設情況下,Spark 不会對工作階段視窗聚合執行部分聚合,因為在分組之前需要在本地分割區中進行額外排序。對於每個本地分割區,相同群組金鑰中只有少數輸入列的情況,這種方式效果較好,但對於本地分割區中有許多輸入列具有相同群組金鑰的情況,儘管有額外的排序,執行部分聚合仍可以顯著提升效能。
您可以啟用spark.sql.streaming.sessionWindow.merge.sessions.in.local.partition以指示 Spark 執行部分聚合。
時間視窗時間的表示方式
在某些使用案例中,有必要擷取時間視窗的時間表示形式,以將需要時間戳記的運算套用於時間視窗資料。一個範例是串連時間視窗聚合,使用者希望針對時間視窗定義另一個時間視窗。假設有人想要將 5 分鐘時間視窗聚合為 1 小時滾動時間視窗。
有兩種方法可以達成此目的,如下所示
- 使用
window_timeSQL 函數,並將時間視窗欄位作為參數 - 使用
windowSQL 函數,並將時間視窗欄位作為參數
window_time 函數會產生一個時間戳記,代表時間視窗的時間。使用者可以將結果傳遞給 window 函數的參數(或任何需要時間戳記的地方),以執行需要時間戳記的時間視窗操作。
words = ... # streaming DataFrame of schema { timestamp: Timestamp, word: String }
# Group the data by window and word and compute the count of each group
windowedCounts = words.groupBy(
window(words.timestamp, "10 minutes", "5 minutes"),
words.word
).count()
# Group the windowed data by another window and word and compute the count of each group
anotherWindowedCounts = windowedCounts.groupBy(
window(window_time(windowedCounts.window), "1 hour"),
windowedCounts.word
).count()import spark.implicits._
val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
val windowedCounts = words.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word"
).count()
// Group the windowed data by another window and word and compute the count of each group
val anotherWindowedCounts = windowedCounts.groupBy(
window(window_time($"window"), "1 hour"),
$"word"
).count()Dataset<Row> words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
Dataset<Row> windowedCounts = words.groupBy(
functions.window(words.col("timestamp"), "10 minutes", "5 minutes"),
words.col("word")
).count();
// Group the windowed data by another window and word and compute the count of each group
Dataset<Row> anotherWindowedCounts = windowedCounts.groupBy(
functions.window(functions.window_time("window"), "1 hour"),
windowedCounts.col("word")
).count();window 函數不僅會使用時間戳記欄位,還會使用時間視窗欄位。這對於使用者想要套用鏈式時間視窗聚合的情況特別有用。
words = ... # streaming DataFrame of schema { timestamp: Timestamp, word: String }
# Group the data by window and word and compute the count of each group
windowedCounts = words.groupBy(
window(words.timestamp, "10 minutes", "5 minutes"),
words.word
).count()
# Group the windowed data by another window and word and compute the count of each group
anotherWindowedCounts = windowedCounts.groupBy(
window(windowedCounts.window, "1 hour"),
windowedCounts.word
).count()import spark.implicits._
val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
val windowedCounts = words.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word"
).count()
// Group the windowed data by another window and word and compute the count of each group
val anotherWindowedCounts = windowedCounts.groupBy(
window($"window", "1 hour"),
$"word"
).count()Dataset<Row> words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
Dataset<Row> windowedCounts = words.groupBy(
functions.window(words.col("timestamp"), "10 minutes", "5 minutes"),
words.col("word")
).count();
// Group the windowed data by another window and word and compute the count of each group
Dataset<Row> anotherWindowedCounts = windowedCounts.groupBy(
functions.window("window", "1 hour"),
windowedCounts.col("word")
).count();清除聚合狀態的水位標記條件
請務必注意,聚合查詢中的水位標記必須滿足以下條件才能清除狀態(截至 Spark 2.1.1,未來可能會變更)。
-
輸出模式必須是 Append 或 Update。Complete 模式需要保留所有聚合資料,因此無法使用水位標記來捨棄中間狀態。請參閱 輸出模式 部分,以詳細了解每個輸出模式的語意。
-
聚合必須具有事件時間欄位,或在事件時間欄位上有一個
window。 -
withWatermark必須在與聚合中使用的時間戳記欄位相同的欄位上呼叫。例如,df.withWatermark("time", "1 min").groupBy("time2").count()在 Append 輸出模式中無效,因為水位標記定義在與聚合欄位不同的欄位上。 -
withWatermark必須在聚合之前呼叫,才能使用水位標記詳細資料。例如,df.groupBy("time").count().withWatermark("time", "1 min")在 Append 輸出模式中無效。
使用水位標記進行聚合的語意保證
-
水位標記延遲(使用
withWatermark設定)為「2 小時」,保證引擎絕不會捨棄延遲不到 2 小時的任何資料。換句話說,任何延遲不到 2 小時(以事件時間而言)的資料,都保證會被聚合,直到處理到最新的資料為止。 -
但是,保證只在一個方向上是嚴格的。延遲超過 2 小時的資料不保證會被捨棄;它可能會或可能不會被聚合。資料延遲越久,引擎處理它的可能性就越低。
聯結操作
結構化串流支援將串流 Dataset/DataFrame 與靜態 Dataset/DataFrame 結合,以及將串流 Dataset/DataFrame 與另一個串流 Dataset/DataFrame 結合。串流結合的結果會逐步產生,類似於上一部分中串流聚合的結果。在本部分中,我們將探討上述情況中支援的結合類型(例如內部、外部、半外部等)。請注意,在所有支援的結合類型中,與串流 Dataset/DataFrame 結合的結果將與與靜態 Dataset/DataFrame 結合的結果完全相同,後者包含串流中的相同資料。
串流靜態聯結
自 Spark 2.0 推出以來,結構化串流已支援串流與靜態 DataFrame/Dataset 之間的聯結(內部聯結和部分外部聯結類型)。以下是一個簡單的範例。
staticDf = spark.read. ...
streamingDf = spark.readStream. ...
streamingDf.join(staticDf, "type") # inner equi-join with a static DF
streamingDf.join(staticDf, "type", "left_outer") # left outer join with a static DFval staticDf = spark.read. ...
val streamingDf = spark.readStream. ...
streamingDf.join(staticDf, "type") // inner equi-join with a static DF
streamingDf.join(staticDf, "type", "left_outer") // left outer join with a static DFDataset<Row> staticDf = spark.read(). ...;
Dataset<Row> streamingDf = spark.readStream(). ...;
streamingDf.join(staticDf, "type"); // inner equi-join with a static DF
streamingDf.join(staticDf, "type", "left_outer"); // left outer join with a static DFstaticDf <- read.df(...)
streamingDf <- read.stream(...)
joined <- merge(streamingDf, staticDf, sort = FALSE) # inner equi-join with a static DF
joined <- join(
streamingDf,
staticDf,
streamingDf$value == staticDf$value,
"left_outer") # left outer join with a static DF請注意,串流與靜態聯結並非有狀態,因此不需要狀態管理。不過,仍有一些串流與靜態外部聯結類型尚未支援。這些類型已列於 此聯結區段的結尾。
串流串流聯結
在 Spark 2.3 中,我們新增了對串流與串流聯結的支援,也就是說,你可以聯結兩個串流 Datasets/DataFrames。在兩個資料串流之間產生聯結結果的挑戰在於,在任何時間點,資料集的檢視對於聯結的兩側都是不完整的,這使得在輸入之間找到配對變得更加困難。從一個輸入串流收到的任何列都可能與來自另一個輸入串流的任何未來尚未收到的列配對。因此,對於兩個輸入串流,我們將過去的輸入緩衝為串流狀態,以便我們可以將每個未來的輸入與過去的輸入配對,並據此產生聯結結果。此外,類似於串流聚合,我們會自動處理延遲的、順序錯誤的資料,並可以使用浮水印限制狀態。讓我們討論支援的不同串流與串流聯結類型以及如何使用它們。
具有可選浮水印的內部聯結
支援任何類型的欄位上的內部聯結以及任何類型的聯結條件。不過,隨著串流執行,串流狀態的大小將持續無限增加,因為所有過去的輸入都必須儲存,因為任何新的輸入都可能與過去的任何輸入配對。若要避免無界狀態,你必須定義額外的聯結條件,以便無限舊的輸入無法與未來的輸入配對,因此可以從狀態中清除。換句話說,你必須在聯結中執行下列額外步驟。
-
在兩個輸入上定義浮水印延遲,以便引擎知道輸入可以延遲多久(類似於串流聚合)
-
定義兩個輸入之間的事件時間約束,以便引擎可以找出一個輸入的舊列何時不再需要(即無法滿足時間約束)與另一個輸入配對。此約束可以用兩種方式之一定義。
-
時間範圍聯結條件(例如
...JOIN ON leftTime BETWEEN rightTime AND rightTime + INTERVAL 1 HOUR), -
在事件時間視窗上聯結(例如
...JOIN ON leftTimeWindow = rightTimeWindow)。
-
讓我們透過一個範例來了解這一點。
假設我們要將廣告展示串流(當廣告顯示時)與另一個廣告點擊使用者串流聯結,以關聯展示何時導致可獲利的點擊。若要允許在此串流與串流聯結中清除狀態,你必須指定浮水印延遲和時間約束,如下所示。
-
浮水印延遲:假設曝光和對應的點擊在事件時間中最多分別延遲/順序錯誤 2 小時和 3 小時。
-
事件時間範圍條件:假設點擊可以在對應曝光後 0 秒到 1 小時的時間範圍內發生。
程式碼如下所示。
from pyspark.sql.functions import expr
impressions = spark.readStream. ...
clicks = spark.readStream. ...
# Apply watermarks on event-time columns
impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
# Join with event-time constraints
impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
""")
)import org.apache.spark.sql.functions.expr
val impressions = spark.readStream. ...
val clicks = spark.readStream. ...
// Apply watermarks on event-time columns
val impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
val clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
// Join with event-time constraints
impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
""")
)import static org.apache.spark.sql.functions.expr
Dataset<Row> impressions = spark.readStream(). ...
Dataset<Row> clicks = spark.readStream(). ...
// Apply watermarks on event-time columns
Dataset<Row> impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours");
Dataset<Row> clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours");
// Join with event-time constraints
impressionsWithWatermark.join(
clicksWithWatermark,
expr(
"clickAdId = impressionAdId AND " +
"clickTime >= impressionTime AND " +
"clickTime <= impressionTime + interval 1 hour ")
);impressions <- read.stream(...)
clicks <- read.stream(...)
# Apply watermarks on event-time columns
impressionsWithWatermark <- withWatermark(impressions, "impressionTime", "2 hours")
clicksWithWatermark <- withWatermark(clicks, "clickTime", "3 hours")
# Join with event-time constraints
joined <- join(
impressionsWithWatermark,
clicksWithWatermark,
expr(
paste(
"clickAdId = impressionAdId AND",
"clickTime >= impressionTime AND",
"clickTime <= impressionTime + interval 1 hour"
)))使用浮水印進行串流串流內部聯結的語意保證
這類似於 浮水印在聚合上提供的保證。「2 小時」的浮水印延遲保證引擎絕不會捨棄延遲不到 2 小時的任何資料。但延遲超過 2 小時的資料可能會或可能不會被處理。
具有浮水印的外部聯結
儘管浮水印 + 事件時間限制對內部聯結是選用的,但對外部聯結則必須指定。這是因為要在外聯結中產生 NULL 結果,引擎必須知道輸入列何時不會與未來任何資料相符。因此,必須指定浮水印 + 事件時間限制才能產生正確的結果。因此,包含外部聯結的查詢看起來會很像先前的廣告獲利範例,只不過會有一個額外的參數指定為外部聯結。
impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
"""),
"leftOuter" # can be "inner", "leftOuter", "rightOuter", "fullOuter", "leftSemi"
)impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
"""),
joinType = "leftOuter" // can be "inner", "leftOuter", "rightOuter", "fullOuter", "leftSemi"
)impressionsWithWatermark.join(
clicksWithWatermark,
expr(
"clickAdId = impressionAdId AND " +
"clickTime >= impressionTime AND " +
"clickTime <= impressionTime + interval 1 hour "),
"leftOuter" // can be "inner", "leftOuter", "rightOuter", "fullOuter", "leftSemi"
);joined <- join(
impressionsWithWatermark,
clicksWithWatermark,
expr(
paste(
"clickAdId = impressionAdId AND",
"clickTime >= impressionTime AND",
"clickTime <= impressionTime + interval 1 hour"),
"left_outer" # can be "inner", "left_outer", "right_outer", "full_outer", "left_semi"
))使用浮水印進行串流串流外部聯結的語意保證
外部聯結在浮水印延遲以及資料是否會被捨棄方面具有與 內部聯結 相同的保證。
注意事項
關於如何產生外部結果,有一些重要的特性需要注意。
-
外部 NULL 結果會延遲產生,延遲時間取決於指定的浮水印延遲和時間範圍條件。這是因為引擎必須等待那麼久才能確保沒有相符資料,而且未來也不會再有相符資料。
-
在微批次引擎中的目前實作中,浮水印會在微批次結束時推進,而下一個微批次會使用更新的浮水印清除狀態和輸出外部結果。由於我們僅在有新資料要處理時才會觸發微批次,因此如果串流中沒有收到新資料,外部結果的產生可能會延遲。簡而言之,如果被聯結的兩個輸入串流有一段時間沒有收到資料,外部(兩種情況,左或右)輸出可能會延遲。
具有浮水印的半聯結
半聯結會傳回與右方相符的關係左方的值。它也稱為左半聯結。與外部聯結類似,必須為半聯結指定浮水印 + 事件時間限制。這是為了驅逐左方未相符的輸入列,引擎必須知道左方的輸入列何時不會與未來右方的任何資料相符。
使用浮水印進行串流串流半聯結的語意保證
半聯結與內部聯結在水印延遲和資料是否會被捨棄方面具有相同的保證。
串流查詢中聯結的支援矩陣
| 左輸入 | 右輸入 | 聯結類型 | |
|---|---|---|---|
| 靜態 | 靜態 | 所有類型 | 支援,因為它不在串流資料中,即使它可能存在於串流查詢中 |
| 串流 | 靜態 | 內部 | 支援,無狀態 |
| 左外部 | 支援,無狀態 | ||
| 右外部 | 不支援 | ||
| 全外部 | 不支援 | ||
| 左半聯結 | 支援,無狀態 | ||
| 靜態 | 串流 | 內部 | 支援,無狀態 |
| 左外部 | 不支援 | ||
| 右外部 | 支援,無狀態 | ||
| 全外部 | 不支援 | ||
| 左半聯結 | 不支援 | ||
| 串流 | 串流 | 內部 | 支援,可選擇在兩側指定水印 + 狀態清除的時間限制 |
| 左外部 | 有條件支援,必須在右邊指定水印 + 時間限制才能得到正確的結果,可選擇在左邊指定水印以清除所有狀態 | ||
| 右外部 | 有條件支援,必須在左邊指定水印 + 時間限制才能得到正確的結果,可選擇在右邊指定水印以清除所有狀態 | ||
| 全外部 | 有條件支援,必須在其中一側指定水印 + 時間限制才能得到正確的結果,可選擇在另一側指定水印以清除所有狀態 | ||
| 左半聯結 | 有條件支援,必須在右邊指定水印 + 時間限制才能得到正確的結果,可選擇在左邊指定水印以清除所有狀態 | ||
關於支援聯結的附加詳細資訊
-
聯結可以串接,也就是說,您可以執行
df1.join(df2, ...).join(df3, ...).join(df4, ....)。 -
從 Spark 2.4 開始,只有當查詢處於附加輸出模式時,您才能使用聯結。其他輸出模式尚不支援。
-
您不能在聯結之前和之後使用 mapGroupsWithState 和 flatMapGroupsWithState。
在附加輸出模式中,您可以建構一個具有非映射類運算的查詢,例如聚合、重複資料刪除、串流串流聯結在聯結之前/之後。
例如,以下是兩個串流中時間視窗聚合的範例,後面接著具有事件時間視窗的串流串流聯結
val clicksWindow = clicksWithWatermark
.groupBy(window("clickTime", "1 hour"))
.count()
val impressionsWindow = impressionsWithWatermark
.groupBy(window("impressionTime", "1 hour"))
.count()
clicksWindow.join(impressionsWindow, "window", "inner")Dataset<Row> clicksWindow = clicksWithWatermark
.groupBy(functions.window(clicksWithWatermark.col("clickTime"), "1 hour"))
.count();
Dataset<Row> impressionsWindow = impressionsWithWatermark
.groupBy(functions.window(impressionsWithWatermark.col("impressionTime"), "1 hour"))
.count();
clicksWindow.join(impressionsWindow, "window", "inner");clicksWindow = clicksWithWatermark.groupBy(
clicksWithWatermark.clickAdId,
window(clicksWithWatermark.clickTime, "1 hour")
).count()
impressionsWindow = impressionsWithWatermark.groupBy(
impressionsWithWatermark.impressionAdId,
window(impressionsWithWatermark.impressionTime, "1 hour")
).count()
clicksWindow.join(impressionsWindow, "window", "inner")以下是另一個串流串流聯結的範例,具有時間範圍聯結條件,後面接著時間視窗聚合
val joined = impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
"""),
joinType = "leftOuter" // can be "inner", "leftOuter", "rightOuter", "fullOuter", "leftSemi"
)
joined
.groupBy($"clickAdId", window($"clickTime", "1 hour"))
.count()Dataset<Row> joined = impressionsWithWatermark.join(
clicksWithWatermark,
expr(
"clickAdId = impressionAdId AND " +
"clickTime >= impressionTime AND " +
"clickTime <= impressionTime + interval 1 hour "),
"leftOuter" // can be "inner", "leftOuter", "rightOuter", "fullOuter", "leftSemi"
);
joined
.groupBy(joined.col("clickAdId"), functions.window(joined.col("clickTime"), "1 hour"))
.count();joined = impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
"""),
"leftOuter" # can be "inner", "leftOuter", "rightOuter", "fullOuter", "leftSemi"
)
joined.groupBy(
joined.clickAdId,
window(joined.clickTime, "1 hour")
).count()串流資料重複消除
您可以使用事件中的唯一識別碼來刪除資料串流中的記錄。這與使用唯一識別碼欄位對靜態資料進行重複資料刪除完全相同。查詢將儲存來自先前記錄的必要資料量,以便它可以過濾重複的記錄。與聚合類似,您可以使用或不使用水印進行重複資料刪除。
-
使用水印 - 如果重複記錄到達的延遲時間有一個上限,則您可以定義事件時間欄位上的水印,並使用 guid 和事件時間欄位進行重複資料刪除。查詢將使用水印從過去記錄中移除舊狀態資料,這些記錄預計不再會收到任何重複資料。這會限制查詢必須維護的狀態量。
-
不使用水印 - 由於重複記錄到達的時間沒有限制,因此查詢會將來自所有過去記錄的資料儲存為狀態。
streamingDf = spark.readStream. ...
# Without watermark using guid column
streamingDf.dropDuplicates("guid")
# With watermark using guid and eventTime columns
streamingDf \
.withWatermark("eventTime", "10 seconds") \
.dropDuplicates("guid", "eventTime")val streamingDf = spark.readStream. ... // columns: guid, eventTime, ...
// Without watermark using guid column
streamingDf.dropDuplicates("guid")
// With watermark using guid and eventTime columns
streamingDf
.withWatermark("eventTime", "10 seconds")
.dropDuplicates("guid", "eventTime")Dataset<Row> streamingDf = spark.readStream(). ...; // columns: guid, eventTime, ...
// Without watermark using guid column
streamingDf.dropDuplicates("guid");
// With watermark using guid and eventTime columns
streamingDf
.withWatermark("eventTime", "10 seconds")
.dropDuplicates("guid", "eventTime");streamingDf <- read.stream(...)
# Without watermark using guid column
streamingDf <- dropDuplicates(streamingDf, "guid")
# With watermark using guid and eventTime columns
streamingDf <- withWatermark(streamingDf, "eventTime", "10 seconds")
streamingDf <- dropDuplicates(streamingDf, "guid", "eventTime")特別針對串流,您可以使用事件中的唯一識別碼在資料串流中刪除重複的記錄,範圍在水印的時間範圍內。例如,如果您將水印的延遲閾值設定為「1 小時」,則可以在 1 小時內發生的重複事件正確刪除重複資料。(有關更多詳細資訊,請參閱 dropDuplicatesWithinWatermark 的 API 文件。)
這可用於處理事件時間欄位無法成為唯一識別碼的一部分之使用案例,這主要是因為相同記錄的事件時間有某種程度的不同。(例如,在寫入時發出事件時間的非冪等寫入器)
建議使用者將浮水印的延遲閾值設定為重複事件之間最大時間戳記差異的長度。
此功能需要在串流 DataFrame/Dataset 中設定具有延遲閾值的浮水印。
streamingDf = spark.readStream. ...
# deduplicate using guid column with watermark based on eventTime column
streamingDf \
.withWatermark("eventTime", "10 hours") \
.dropDuplicatesWithinWatermark("guid")val streamingDf = spark.readStream. ... // columns: guid, eventTime, ...
// deduplicate using guid column with watermark based on eventTime column
streamingDf
.withWatermark("eventTime", "10 hours")
.dropDuplicatesWithinWatermark("guid")Dataset<Row> streamingDf = spark.readStream(). ...; // columns: guid, eventTime, ...
// deduplicate using guid column with watermark based on eventTime column
streamingDf
.withWatermark("eventTime", "10 hours")
.dropDuplicatesWithinWatermark("guid");處理多個浮水印的政策
串流查詢可以有多個輸入串流,這些串流會進行合併或聯結。每個輸入串流可能都有不同的延遲資料閾值,而狀態操作需要容忍這些閾值。您可以在每個輸入串流上使用 withWatermarks("eventTime", delay) 來指定這些閾值。例如,請考慮一個查詢,其中包含 inputStream1 和 inputStream2 之間的串流串流聯結。
inputStream1.withWatermark("eventTime1", "1 hour")
.join(
inputStream2.withWatermark("eventTime2", "2 hours"),
joinCondition)在執行查詢時,結構化串流會個別追蹤在每個輸入串流中看到最大事件時間,根據對應的延遲計算浮水印,並選擇一個單一全域浮水印與它們一起用於狀態操作。預設會選擇最小值作為全域浮水印,因為這樣可以確保當其中一個串流落後於其他串流時(例如,其中一個串流由於上游故障而停止接收資料),不會意外地將任何資料視為過於延遲而捨棄。換句話說,全域浮水印將安全地以最慢串流的速度移動,而查詢輸出也會相應地延遲。
不過,在某些情況下,您可能希望即使表示要捨棄最慢串流中的資料,也要更快取得結果。自 Spark 2.4 起,您可以將多重浮水印政策設定為選擇最大值作為全域浮水印,方法是將 SQL 組態 spark.sql.streaming.multipleWatermarkPolicy 設定為 max(預設為 min)。這會讓全域浮水印以最快串流的速度移動。不過,副作用是較慢串流中的資料將會被積極捨棄。因此,請明智地使用此組態。
任意有狀態操作
許多用例需要比聚合更進階的狀態操作。例如,在許多用例中,您必須從事件資料串流追蹤工作階段。為了進行此類工作階段化,您必須將任意類型的資料儲存為狀態,並使用每個觸發器中的資料串流事件對狀態執行任意操作。自 Spark 2.2 起,這可以使用操作 mapGroupsWithState 和更強大的操作 flatMapGroupsWithState 來完成。這兩個操作都允許您對群組化的資料集套用使用者定義的程式碼,以更新使用者定義的狀態。有關更具體的詳細資訊,請參閱 API 文件 (Scala/Java) 和範例 (Scala/Java).
雖然 Spark 無法檢查並強制執行,但狀態函數應根據輸出模式的語意來實作。例如,在更新模式中,Spark 並不預期狀態函數會發出比目前浮水印加上允許的延遲記錄時間更舊的列,而在附加模式中,狀態函數可以發出這些列。
不支援的操作
有幾個 DataFrame/Dataset 操作不支援串流式 DataFrame/Dataset。其中一些如下。
-
在串流式資料集上不支援限制和取前 N 列。
-
在串流式資料集上不支援相異操作。
-
排序操作僅在串流式資料集上支援聚合後和在完整輸出模式中。
-
在串流式資料集上不支援少數類型的外部聯結。有關更多詳細資訊,請參閱 聯結操作部分中的支援矩陣。
-
在串流式資料集上不支援對多個狀態操作進行串連,且不支援更新和完整模式。
- 此外,在附加模式中不支援 mapGroupsWithState/flatMapGroupsWithState 操作後接其他狀態操作。
- 已知的解決方法是將串流式查詢拆分為多個查詢,每個查詢有一個狀態操作,並確保每個查詢的端對端完全執行一次。確保最後一個查詢的端對端完全執行一次是可選的。
此外,有一些 Dataset 方法無法在串流式資料集上執行。它們是會立即執行查詢並傳回結果的動作,這在串流式資料集上沒有意義。相反地,這些功能可以透過明確啟動串流式查詢來完成(請參閱下一部分的相關資訊)。
-
count()- 無法從串流資料集傳回單一計數。請改用ds.groupBy().count(),它會傳回包含執行計數的串流資料集。 -
foreach()- 請改用ds.writeStream.foreach(...)(請參閱下一節)。 -
show()- 請改用主控台接收器 (請參閱下一節)。
如果您嘗試執行任何這些作業,您會看到類似「作業 XYZ 不支援串流資料框/資料集」的 AnalysisException。雖然其中一些作業可能在 Spark 的未來版本中獲得支援,但其他作業在串流資料上實作時本質上難以有效率。例如,不支援對輸入串流進行排序,因為它需要追蹤串流中接收的所有資料。因此,這在執行時本質上難以有效率。
狀態儲存
狀態儲存庫是提供讀取和寫入作業的版本化鍵值儲存庫。在結構化串流中,我們使用狀態儲存庫提供者來處理批次之間的狀態作業。有兩個內建的狀態儲存庫提供者實作。最終使用者也可以透過延伸 StateStoreProvider 介面來實作自己的狀態儲存庫提供者。
HDFS 狀態儲存提供者
HDFS 後端狀態儲存庫提供者是 [[StateStoreProvider]] 和 [[StateStore]] 的預設實作,其中所有資料都儲存在第一階段的記憶體映射中,然後由 HDFS 相容檔案系統中的檔案備份。儲存庫的所有更新都必須以交易方式進行,且每組更新都會增加儲存庫的版本。這些版本可用於在儲存庫的正確版本上重新執行更新 (透過 RDD 作業中的重試),並重新產生儲存庫版本。
RocksDB 狀態儲存實作
從 Spark 3.2 開始,我們新增一個內建的狀態儲存庫實作,RocksDB 狀態儲存庫提供者。
如果您的串流查詢中有狀態作業 (例如串流聚合、串流 dropDuplicates、串流串流聯結、mapGroupsWithState 或 flatMapGroupsWithState),而且您想要在狀態中維護數百萬個金鑰,那麼您可能會遇到與大型 JVM 垃圾回收 (GC) 暫停相關的問題,導致微批次處理時間有很大的差異。這是因為根據 HDFSBackedStateStore 的實作,狀態資料會保留在執行器的 JVM 記憶體中,而且大量的狀態物件會對 JVM 造成記憶體壓力,導致 GC 暫停時間變長。
在這種情況下,您可以選擇使用基於 RocksDB 的更最佳化的狀態管理解決方案。此解決方案不會將狀態保留在 JVM 記憶體中,而是使用 RocksDB 有效地管理原生記憶體和本機磁碟中的狀態。此外,結構化串流會自動將對此狀態的任何變更儲存到您提供的檢查點位置,從而提供完整的容錯保證 (與預設狀態管理相同)。
若要啟用新的內建狀態儲存實作,請將 spark.sql.streaming.stateStore.providerClass 設為 org.apache.spark.sql.execution.streaming.state.RocksDBStateStoreProvider。
以下是關於狀態儲存提供者的 RocksDB 執行個體的組態
| 組態名稱 | 說明 | 預設值 |
|---|---|---|
| spark.sql.streaming.stateStore.rocksdb.compactOnCommit | 是否執行 RocksDB 執行個體的範圍壓縮以進行提交作業 | False |
| spark.sql.streaming.stateStore.rocksdb.changelogCheckpointing.enabled | 是否在 RocksDB StateStore 提交期間上傳變更記錄而非快照 | False |
| spark.sql.streaming.stateStore.rocksdb.blockSizeKB | RocksDB BlockBasedTable(RocksDB 的預設 SST 檔案格式)中每個區塊封裝的使用者資料近似大小(以 KB 為單位)。 | 4 |
| spark.sql.streaming.stateStore.rocksdb.blockCacheSizeMB | 區塊快取的容量(以 MB 為單位)。 | 8 |
| spark.sql.streaming.stateStore.rocksdb.lockAcquireTimeoutMs | 在 RocksDB 執行個體的載入作業中取得鎖定的等待時間(以毫秒為單位)。 | 60000 |
| spark.sql.streaming.stateStore.rocksdb.maxOpenFiles | RocksDB 執行個體可使用的開啟檔案數量。-1 的值表示開啟的檔案會永遠保持開啟。如果達到開啟檔案的限制,RocksDB 會從開啟檔案快取中驅逐項目,並關閉這些檔案描述符,然後從快取中移除這些項目。 | -1 |
| spark.sql.streaming.stateStore.rocksdb.resetStatsOnLoad | 是否在載入時重設 RocksDB 的所有計時器和直方圖統計資料。 | True |
| spark.sql.streaming.stateStore.rocksdb.trackTotalNumberOfRows | 是否追蹤狀態儲存中的總列數。請參閱 效能層面考量 中的詳細資訊。 | True |
| spark.sql.streaming.stateStore.rocksdb.writeBufferSizeMB | RocksDB 中 MemTable 的最大大小。-1 的值表示將使用 RocksDB 內部的預設值 | -1 |
| spark.sql.streaming.stateStore.rocksdb.maxWriteBufferNumber | RocksDB 中 MemTable 的最大數量(包括活動和不可變動)。-1 的值表示將使用 RocksDB 內部的預設值 | -1 |
| spark.sql.streaming.stateStore.rocksdb.boundedMemoryUsage | 是否限制單一節點上 RocksDB 狀態儲存執行個體的總體記憶體使用量。 | false |
| spark.sql.streaming.stateStore.rocksdb.maxMemoryUsageMB | 單一節點上 RocksDB 狀態儲存執行個體的總體記憶體限制(以 MB 為單位)。 | 500 |
| spark.sql.streaming.stateStore.rocksdb.writeBufferCacheRatio | 使用 maxMemoryUsageMB 在單一節點上分配給所有 RocksDB 執行個體的記憶體中,要由寫入緩衝區佔用的總體記憶體(以小數表示)。 | 0.5 |
| spark.sql.streaming.stateStore.rocksdb.highPriorityPoolRatio | 總記憶體將由高優先順序池中的區塊佔用,作為單一節點上所有 RocksDB 實例使用 maxMemoryUsageMB 分配的記憶體的一部分。 | 0.1 |
RocksDB 狀態儲存記憶體管理
RocksDB 為不同的物件分配記憶體,例如記憶表、區塊快取和篩選器/索引區塊。如果未設定限制,多個實例中的 RocksDB 記憶體使用量可能會無限增加,並可能導致 OOM(記憶體不足)問題。RocksDB 提供一種方式,透過使用寫入緩衝區管理員功能,限制在單一節點上執行的所有資料庫實例的記憶體使用量。如果您要在 Spark 結構化串流部署中限制 RocksDB 記憶體使用量,可以透過將 spark.sql.streaming.stateStore.rocksdb.boundedMemoryUsage 設定值設定為 true 來啟用此功能。您也可以透過將 spark.sql.streaming.stateStore.rocksdb.maxMemoryUsageMB 值設定為靜態數字或節點上可用實體記憶體的一部分,來決定 RocksDB 實例的最大允許記憶體。也可以透過將 spark.sql.streaming.stateStore.rocksdb.writeBufferSizeMB 和 spark.sql.streaming.stateStore.rocksdb.maxWriteBufferNumber 設定為所需值,來設定個別 RocksDB 實例的限制。預設情況下,這些設定會使用 RocksDB 內部的預設值。
RocksDB 狀態儲存變更日誌檢查點
在較新版本的 Spark 中,為 RocksDB 狀態儲存引入了變更日誌檢查點。RocksDB 狀態儲存的傳統檢查點機制是增量快照檢查點,其中會將 RocksDB 實例的清單檔案和新產生的 RocksDB SST 檔案上傳到耐用的儲存空間。變更日誌檢查點不會上傳 RocksDB 實例的資料檔案,而是上傳自上次檢查點以來對狀態所做的變更以確保耐用性。快照會定期在背景中保留,以進行可預測的故障復原和變更日誌修剪。變更日誌檢查點避免了擷取和上傳 RocksDB 實例快照的成本,並大幅減少串流查詢延遲。
預設情況下,變更記錄檢查點功能已停用。您可以設定 spark.sql.streaming.stateStore.rocksdb.changelogCheckpointing.enabled 設定檔為 true,以啟用 RocksDB 狀態儲存變更記錄檢查點。變更記錄檢查點功能設計為與傳統的檢查點機制向後相容。RocksDB 狀態儲存提供者提供無縫支援,讓您可以在兩個檢查點機制之間雙向轉換。這讓您可以在不捨棄舊狀態檢查點的情況下,利用變更記錄檢查點功能的效能優勢。在支援變更記錄檢查點功能的 Spark 版本中,您可以透過在 Spark 會話中啟用變更記錄檢查點功能,將串流查詢從舊版 Spark 遷移至變更記錄檢查點。反之,您可以在較新版本的 Spark 中安全停用變更記錄檢查點功能,然後任何已使用變更記錄檢查點功能執行的查詢都將切換回傳統檢查點。您需要重新啟動串流查詢,才能套用檢查點機制的變更,但在此過程中您不會觀察到任何效能降低。
效能面向考量
- 您可能想要停用總列數追蹤,以在 RocksDB 狀態儲存中獲得更好的效能。
追蹤列數會在寫入作業中帶來額外的查詢 - 建議您嘗試關閉 RocksDB 狀態儲存的調整設定檔,特別是狀態運算子的指標值很大時 - numRowsUpdated、numRowsRemoved。
您可以在重新啟動查詢時變更設定檔,這讓您可以在「可觀察性與效能」之間變更權衡決策。如果停用設定檔,狀態中的列數 (numTotalStateRows) 將報告為 0。
狀態儲存和工作負載區域性
有狀態作業會將執行器狀態儲存中的事件儲存在狀態儲存中。狀態儲存會佔用記憶體和磁碟空間等資源來儲存狀態。因此,讓狀態儲存提供者在不同的串流批次中於同一個執行器中執行會更有效率。變更狀態儲存提供者的位置需要額外的負擔來載入檢查點狀態。從檢查點載入狀態的負擔取決於外部儲存和狀態大小,這往往會損害微批次執行的延遲。對於某些使用案例,例如處理非常大的狀態資料,從檢查點狀態載入新的狀態儲存提供者會非常耗時且低效率。
結構化串流查詢中的有狀態作業仰賴 Spark 的 RDD 的偏好位置功能,才能在同一個執行器上執行狀態儲存提供者。如果在下一批次中,對應的狀態儲存提供者再次排程在此執行器上,它可以重複使用先前的狀態,並節省載入檢查點狀態的時間。
然而,一般來說,偏好的位置並非硬性要求,Spark 仍有可能將工作排程到偏好位置以外的執行器。在這種情況下,Spark 會從新執行器上的檢查點狀態載入狀態儲存提供者。先前批次執行的狀態儲存提供者並不會立即卸載。Spark 會執行一項維護工作,檢查並卸載執行器上不活躍的狀態儲存提供者。
透過變更與工作排程相關的 Spark 組態,例如 spark.locality.wait,使用者可以設定 Spark 等待啟動資料本機工作的時間長度。對於結構化串流中的有狀態運算,可用於讓狀態儲存提供者在批次間於同一執行器上執行。
特別是對於內建的 HDFS 狀態儲存提供者,使用者可以檢查狀態儲存指標,例如 loadedMapCacheHitCount 和 loadedMapCacheMissCount。理想情況下,最好將快取遺失次數降至最低,這表示 Spark 載入檢查點狀態時不會浪費太多時間。使用者可以增加 Spark 本機等待組態,以避免在批次間於不同執行器中載入狀態儲存提供者。
啟動串流查詢
定義最終結果 DataFrame/Dataset 後,剩下的就是啟動串流運算。為此,您必須使用 DataStreamWriter (Scala/Java/Python 文件) 通過 Dataset.writeStream() 傳回。您必須在此介面中指定下列其中一項或多項。
-
輸出接收器詳細資料:資料格式、位置等。
-
輸出模式:指定寫入輸出接收器的內容。
-
查詢名稱:選擇性地指定查詢的唯一名稱以供識別。
-
觸發間隔:選擇性地指定觸發間隔。如果未指定,系統會在先前處理完成後立即檢查是否有新資料可用。如果因為先前處理尚未完成而錯過觸發時間,系統將立即觸發處理。
-
檢查點位置:對於可以保證端對端容錯的某些輸出接收器,請指定系統將寫入所有檢查點資訊的位置。這應該是 HDFS 相容容錯檔案系統中的目錄。檢查點語意在下一節中會更詳細地討論。
輸出模式
有幾種輸出模式。
-
追加模式(預設) - 這是預設模式,只有自上次觸發以來新增至結果表的列才會輸出至儲存槽。這僅支援那些新增至結果表的列永遠不會變更的查詢。因此,此模式保證每列只會輸出一次(假設儲存槽具有容錯能力)。例如,只有
select、where、map、flatMap、filter、join等的查詢會支援追加模式。 -
完整模式 - 每個觸發後,整個結果表都會輸出至儲存槽。這支援聚合查詢。
-
更新模式 - (自 Spark 2.1.1 起可用)只有自上次觸發以來更新的結果表中的列才會輸出至儲存槽。更多資訊會在未來版本中新增。
不同類型的串流查詢支援不同的輸出模式。以下是相容性矩陣。
| 查詢類型 | 支援的輸出模式 | 注意事項 | |
|---|---|---|---|
| 有聚合的查詢 | 有浮水印的事件時間聚合 | 追加、更新、完整 |
追加模式使用浮水印來捨棄舊聚合狀態。但是,視窗聚合的輸出會延後在 withWatermark() 中指定的最後門檻值,因為根據模式語意,列只能在最終確定後(即在超過浮水印後)才能新增至結果表。請參閱 延遲資料 區段以取得更多詳細資料。
更新模式使用浮水印來捨棄舊聚合狀態。 完整模式不會捨棄舊聚合狀態,因為根據定義,此模式會保留結果表中的所有資料。 |
| 其他聚合 | 完整、更新 |
由於未定義浮水印(僅在其他類別中定義),因此不會捨棄舊聚合狀態。
不支援追加模式,因為聚合可以更新,因此會違反此模式的語意。 |
|
有 mapGroupsWithState 的查詢 |
更新 |
不允許在有 mapGroupsWithState 的查詢中進行聚合。
|
|
有 flatMapGroupsWithState 的查詢 |
追加操作模式 | 追加 |
flatMapGroupsWithState 後允許聚合。
|
| 更新操作模式 | 更新 |
在使用 flatMapGroupsWithState 的查詢中不允許聚合。
|
|
使用 joins 的查詢 |
追加 | 尚未支援更新和完成模式。有關支援的連接類型,請參閱 串流查詢中的連接操作區段中的支援矩陣 以取得更多詳細資料。 | |
| 其他查詢 | 附加、更新 | 由於無法將所有未聚合資料保留在結果資料表中,因此不支援完成模式。 | |
輸出接收器
有幾種類型的內建輸出接收器。
- 檔案接收器 - 將輸出儲存到目錄中。
writeStream
.format("parquet") // can be "orc", "json", "csv", etc.
.option("path", "path/to/destination/dir")
.start()- Kafka 接收器 - 將輸出儲存到 Kafka 中的一個或多個主題。
writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "updates")
.start()- Foreach 接收器 - 對輸出中的記錄執行任意運算。請參閱本區段後面的內容以取得更多詳細資料。
writeStream
.foreach(...)
.start()- 主控台接收器 (用於除錯) - 每當有觸發器時,就會將輸出列印到主控台/標準輸出。支援附加和完成輸出模式。這應使用於低資料量上的除錯目的,因為每次觸發後,整個輸出都會收集並儲存在驅動程式的記憶體中。
writeStream
.format("console")
.start()- 記憶體接收器 (用於除錯) - 輸出儲存在記憶體中,作為記憶體內資料表。支援附加和完成輸出模式。這應使用於低資料量上的除錯目的,因為每次觸發後,整個輸出都會收集並儲存在驅動程式的記憶體中。因此,請小心使用。
writeStream
.format("memory")
.queryName("tableName")
.start()有些接收器並非容錯的,因為它們無法保證輸出持續存在,而且僅用於除錯目的。請參閱 容錯語意 的前面區段。以下是 Spark 中所有接收器的詳細資料。
| 接收器 | 支援的輸出模式 | 選項 | 容錯 | 注意事項 |
|---|---|---|---|---|
| 檔案接收器 | 追加 |
path:輸出目錄的路徑,必須指定。retention:輸出檔案的存活時間 (TTL)。批次提交時間早於 TTL 的輸出檔案最終會從元資料記錄中排除。這表示讀取接收器輸出目錄的讀取器查詢可能不會處理它們。您可以提供時間的字串格式作為值。(例如「12h」、「7d」等) 預設情況下,它已停用。
有關檔案格式特定選項,請參閱 DataFrameWriter 中的相關方法 (Scala/Java/Python/R)。例如,有關「parquet」格式選項,請參閱 DataFrameWriter.parquet()
|
是 (完全一次) | 支援寫入分割資料表。依時間分割可能很有用。 |
| Kafka Sink | 追加、更新、完整 | 請參閱 Kafka 整合指南 | 是(至少一次) | 詳細資訊請參閱 Kafka 整合指南 |
| Foreach Sink | 追加、更新、完整 | 無 | 是(至少一次) | 詳細資訊請參閱 下一節 |
| ForeachBatch Sink | 追加、更新、完整 | 無 | 取決於實作 | 詳細資訊請參閱 下一節 |
| Console Sink | 追加、更新、完整 |
numRows:每次觸發列印的列數(預設:20)
truncate:是否在輸出過長時將其截斷(預設:true)
|
否 | |
| Memory Sink | 附加、完成 | 無 | 否。但在完成模式中,重新啟動的查詢會重新建立完整的表格。 | 表格名稱是查詢名稱。 |
請注意,您必須呼叫 start() 才能實際開始執行查詢。這會傳回一個 StreamingQuery 物件,它是持續執行處理的控制項。您可以使用此物件來管理查詢,我們將在下一小節中討論。現在,讓我們透過幾個範例了解這一切。
# ========== DF with no aggregations ==========
noAggDF = deviceDataDf.select("device").where("signal > 10")
# Print new data to console
noAggDF \
.writeStream \
.format("console") \
.start()
# Write new data to Parquet files
noAggDF \
.writeStream \
.format("parquet") \
.option("checkpointLocation", "path/to/checkpoint/dir") \
.option("path", "path/to/destination/dir") \
.start()
# ========== DF with aggregation ==========
aggDF = df.groupBy("device").count()
# Print updated aggregations to console
aggDF \
.writeStream \
.outputMode("complete") \
.format("console") \
.start()
# Have all the aggregates in an in-memory table. The query name will be the table name
aggDF \
.writeStream \
.queryName("aggregates") \
.outputMode("complete") \
.format("memory") \
.start()
spark.sql("select * from aggregates").show() # interactively query in-memory table// ========== DF with no aggregations ==========
val noAggDF = deviceDataDf.select("device").where("signal > 10")
// Print new data to console
noAggDF
.writeStream
.format("console")
.start()
// Write new data to Parquet files
noAggDF
.writeStream
.format("parquet")
.option("checkpointLocation", "path/to/checkpoint/dir")
.option("path", "path/to/destination/dir")
.start()
// ========== DF with aggregation ==========
val aggDF = df.groupBy("device").count()
// Print updated aggregations to console
aggDF
.writeStream
.outputMode("complete")
.format("console")
.start()
// Have all the aggregates in an in-memory table
aggDF
.writeStream
.queryName("aggregates") // this query name will be the table name
.outputMode("complete")
.format("memory")
.start()
spark.sql("select * from aggregates").show() // interactively query in-memory table// ========== DF with no aggregations ==========
Dataset<Row> noAggDF = deviceDataDf.select("device").where("signal > 10");
// Print new data to console
noAggDF
.writeStream()
.format("console")
.start();
// Write new data to Parquet files
noAggDF
.writeStream()
.format("parquet")
.option("checkpointLocation", "path/to/checkpoint/dir")
.option("path", "path/to/destination/dir")
.start();
// ========== DF with aggregation ==========
Dataset<Row> aggDF = df.groupBy("device").count();
// Print updated aggregations to console
aggDF
.writeStream()
.outputMode("complete")
.format("console")
.start();
// Have all the aggregates in an in-memory table
aggDF
.writeStream()
.queryName("aggregates") // this query name will be the table name
.outputMode("complete")
.format("memory")
.start();
spark.sql("select * from aggregates").show(); // interactively query in-memory table# ========== DF with no aggregations ==========
noAggDF <- select(where(deviceDataDf, "signal > 10"), "device")
# Print new data to console
write.stream(noAggDF, "console")
# Write new data to Parquet files
write.stream(noAggDF,
"parquet",
path = "path/to/destination/dir",
checkpointLocation = "path/to/checkpoint/dir")
# ========== DF with aggregation ==========
aggDF <- count(groupBy(df, "device"))
# Print updated aggregations to console
write.stream(aggDF, "console", outputMode = "complete")
# Have all the aggregates in an in memory table. The query name will be the table name
write.stream(aggDF, "memory", queryName = "aggregates", outputMode = "complete")
# Interactively query in-memory table
head(sql("select * from aggregates"))使用 Foreach 和 ForeachBatch
foreach 和 foreachBatch 作業讓您可以套用任意作業和寫入邏輯到串流查詢的輸出。它們有稍微不同的使用案例 - foreach 允許在每一列自訂寫入邏輯,而 foreachBatch 允許在每個微批次的輸出執行任意作業和自訂邏輯。讓我們更詳細地了解它們的用法。
ForeachBatch
foreachBatch(...) 讓您可以指定一個函式,在串流查詢的每個微批次的輸出資料上執行。自 Spark 2.4 起,這在 Scala、Java 和 Python 中受到支援。它需要兩個參數:一個包含微批次輸出資料的 DataFrame 或 Dataset,以及微批次的唯一 ID。
def foreach_batch_function(df, epoch_id):
# Transform and write batchDF
pass
streamingDF.writeStream.foreachBatch(foreach_batch_function).start()streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
// Transform and write batchDF
}.start()streamingDatasetOfString.writeStream().foreachBatch(
new VoidFunction2<Dataset<String>, Long>() {
public void call(Dataset<String> dataset, Long batchId) {
// Transform and write batchDF
}
}
).start();R 尚未受到支援。
使用 foreachBatch,您可以執行下列動作。
- 重複使用現有的批次資料來源 - 對於許多儲存系統,可能尚未提供串流 Sink,但批次查詢可能已經有資料寫入器。使用
foreachBatch,您可以在每個微批次的輸出上使用批次資料寫入器。 - 寫入多個位置 - 如果您要將串流查詢的輸出寫入多個位置,則可以簡單地多次寫入輸出 DataFrame/Dataset。但是,每次寫入嘗試都可能導致輸出資料被重新計算(包括可能重新讀取輸入資料)。為避免重新計算,您應該快取輸出 DataFrame/Dataset,將其寫入多個位置,然後取消快取。以下是綱要。
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.persist()
batchDF.write.format(...).save(...) // location 1
batchDF.write.format(...).save(...) // location 2
batchDF.unpersist()
}- 套用額外的 DataFrame 作業 - 許多 DataFrame 和 Dataset 作業不受串流 DataFrame 支援,因為 Spark 不支援在這些情況中產生增量計畫。使用
foreachBatch,您可以在每個微批次輸出套用其中一些作業。不過,您必須自己推論執行該作業的端對端語意。
注意
- 預設情況下,
foreachBatch僅提供至少一次寫入保證。不過,您可以使用提供給函式的 batchId 作為重複資料刪除的方式,並取得一次性保證。 foreachBatch不適用於連續處理模式,因為它基本上依賴於串流查詢的微批次執行。如果您在連續模式中寫入資料,請改用foreach。
Foreach
如果 foreachBatch 不是一個選項(例如,不存在對應的批次資料寫入器,或連續處理模式),那麼您可以使用 foreach 來表達您的自訂寫入器邏輯。具體來說,您可以透過將資料寫入邏輯分為三個方法來表達:open、process 和 close。自 Spark 2.4 以來,foreach 可用於 Scala、Java 和 Python。
在 Python 中,您可以用兩種方式呼叫 foreach:在函式中或在物件中。函式提供一種表達處理邏輯的簡單方式,但當故障導致重新處理某些輸入資料時,不允許您重複刪除產生的資料。對於這種情況,您必須在物件中指定處理邏輯。
- 首先,函式將列作為輸入。
def process_row(row):
# Write row to storage
pass
query = streamingDF.writeStream.foreach(process_row).start()- 其次,物件有一個 process 方法和選用的 open 和 close 方法
class ForeachWriter:
def open(self, partition_id, epoch_id):
# Open connection. This method is optional in Python.
pass
def process(self, row):
# Write row to connection. This method is NOT optional in Python.
pass
def close(self, error):
# Close the connection. This method in optional in Python.
pass
query = streamingDF.writeStream.foreach(ForeachWriter()).start()在 Scala 中,您必須擴充類別 ForeachWriter (文件).
streamingDatasetOfString.writeStream.foreach(
new ForeachWriter[String] {
def open(partitionId: Long, version: Long): Boolean = {
// Open connection
}
def process(record: String): Unit = {
// Write string to connection
}
def close(errorOrNull: Throwable): Unit = {
// Close the connection
}
}
).start()在 Java 中,您必須擴充類別 ForeachWriter (文件).
streamingDatasetOfString.writeStream().foreach(
new ForeachWriter<String>() {
@Override public boolean open(long partitionId, long version) {
// Open connection
}
@Override public void process(String record) {
// Write string to connection
}
@Override public void close(Throwable errorOrNull) {
// Close the connection
}
}
).start();R 尚未受到支援。
執行語意 當串流查詢啟動時,Spark 會以以下方式呼叫函式或物件的方法
-
此物件的單一副本負責查詢中單一工作所產生的所有資料。換句話說,一個執行個體負責處理以分散方式產生的資料的一個分割區。
-
此物件必須是可序列化的,因為每個工作都會取得所提供物件的新序列化和反序列化副本。因此,強烈建議在呼叫 open() 方法(表示工作已準備好產生資料)之後,執行任何資料寫入初始化(例如,開啟連線或開始交易)。
-
方法的生命週期如下
-
對於每個分割區(其 partition_id 為)
-
對於具有 epoch_id 的串流資料的每個批次/epoch
-
呼叫方法 open(partitionId, epochId)。
-
如果 open(…) 傳回 true,則會針對分割區和批次/epoch 中的每一列呼叫方法 process(row)。
-
呼叫方法 close(error) 傳入處理列時看到的錯誤 (如果有)。
-
-
-
-
如果 open() 方法存在並成功傳回 (不論傳回值為何),則會呼叫 close() 方法 (如果存在),除非 JVM 或 Python 程序在中間發生異常中斷。
-
注意: Spark 無法保證 (partitionId, epochId) 的輸出相同,因此無法使用 (partitionId, epochId) 達到資料重複消除。例如,來源出於某些原因提供不同數量的分割區,Spark 最佳化會變更分割區數量等。請參閱 SPARK-28650 以取得更多詳細資料。如果您需要對輸出進行資料重複消除,請改用
foreachBatch。
串流表格 API
從 Spark 3.1 開始,您也可以使用 DataStreamReader.table() 將資料表讀取為串流資料框,並使用 DataStreamWriter.toTable() 將串流資料框寫入為資料表
spark = ... # spark session
# Create a streaming DataFrame
df = spark.readStream \
.format("rate") \
.option("rowsPerSecond", 10) \
.load()
# Write the streaming DataFrame to a table
df.writeStream \
.option("checkpointLocation", "path/to/checkpoint/dir") \
.toTable("myTable")
# Check the table result
spark.read.table("myTable").show()
# Transform the source dataset and write to a new table
spark.readStream \
.table("myTable") \
.select("value") \
.writeStream \
.option("checkpointLocation", "path/to/checkpoint/dir") \
.format("parquet") \
.toTable("newTable")
# Check the new table result
spark.read.table("newTable").show()val spark: SparkSession = ...
// Create a streaming DataFrame
val df = spark.readStream
.format("rate")
.option("rowsPerSecond", 10)
.load()
// Write the streaming DataFrame to a table
df.writeStream
.option("checkpointLocation", "path/to/checkpoint/dir")
.toTable("myTable")
// Check the table result
spark.read.table("myTable").show()
// Transform the source dataset and write to a new table
spark.readStream
.table("myTable")
.select("value")
.writeStream
.option("checkpointLocation", "path/to/checkpoint/dir")
.format("parquet")
.toTable("newTable")
// Check the new table result
spark.read.table("newTable").show()SparkSession spark = ...
// Create a streaming DataFrame
Dataset<Row> df = spark.readStream()
.format("rate")
.option("rowsPerSecond", 10)
.load();
// Write the streaming DataFrame to a table
df.writeStream()
.option("checkpointLocation", "path/to/checkpoint/dir")
.toTable("myTable");
// Check the table result
spark.read().table("myTable").show();
// Transform the source dataset and write to a new table
spark.readStream()
.table("myTable")
.select("value")
.writeStream()
.option("checkpointLocation", "path/to/checkpoint/dir")
.format("parquet")
.toTable("newTable");
// Check the new table result
spark.read().table("newTable").show();R 中不提供。
如需更多詳細資料,請查看 DataStreamReader (Scala/Java/Python 文件) 和 DataStreamWriter (Scala/Java/Python 文件) 文件。
觸發器
串流查詢的觸發設定會定義串流資料處理的時機,無論查詢是要以具有固定批次間隔的微批次查詢執行,還是以連續處理查詢執行。以下是支援的不同觸發類型。
| 觸發類型 | 說明 |
|---|---|
| 未指定 (預設) | 如果未明確指定觸發設定,則預設會以微批次模式執行查詢,其中微批次會在先前的微批次完成處理後立即產生。 |
| 固定間隔微批次 |
查詢會以微批次模式執行,其中微批次會在使用者指定的間隔中啟動。
|
| 一次性微批次(已棄用) | 查詢只會執行一個微批次來處理所有可用的資料,然後自行停止。這在您想要定期啟動叢集、處理自上次期間以來所有可用的資料,然後關閉叢集的場景中很有用。在某些情況下,這可能會帶來顯著的成本節省。請注意,此觸發器已棄用,建議使用者移轉到立即可用微批次,因為它提供了更好的處理保證、細緻的批次規模,以及更好的漸進式處理水位進展,包括無資料批次。 |
| 立即可用微批次 |
類似於一次性微批次觸發器的查詢,查詢將處理所有可用的資料,然後自行停止。不同之處在於,它會根據來源選項(例如,檔案來源的 maxFilesPerTrigger)在(可能)多個微批次中處理資料,這將帶來更好的查詢可擴充性。
|
| 連續使用固定的檢查點間隔 (實驗性) |
查詢將在新的低延遲、連續處理模式中執行。在以下的 連續處理區段 中深入了解這一點。 |
以下是幾個程式碼範例。
# Default trigger (runs micro-batch as soon as it can)
df.writeStream \
.format("console") \
.start()
# ProcessingTime trigger with two-seconds micro-batch interval
df.writeStream \
.format("console") \
.trigger(processingTime='2 seconds') \
.start()
# One-time trigger (Deprecated, encouraged to use Available-now trigger)
df.writeStream \
.format("console") \
.trigger(once=True) \
.start()
# Available-now trigger
df.writeStream \
.format("console") \
.trigger(availableNow=True) \
.start()
# Continuous trigger with one-second checkpointing interval
df.writeStream
.format("console")
.trigger(continuous='1 second')
.start()import org.apache.spark.sql.streaming.Trigger
// Default trigger (runs micro-batch as soon as it can)
df.writeStream
.format("console")
.start()
// ProcessingTime trigger with two-seconds micro-batch interval
df.writeStream
.format("console")
.trigger(Trigger.ProcessingTime("2 seconds"))
.start()
// One-time trigger (Deprecated, encouraged to use Available-now trigger)
df.writeStream
.format("console")
.trigger(Trigger.Once())
.start()
// Available-now trigger
df.writeStream
.format("console")
.trigger(Trigger.AvailableNow())
.start()
// Continuous trigger with one-second checkpointing interval
df.writeStream
.format("console")
.trigger(Trigger.Continuous("1 second"))
.start()import org.apache.spark.sql.streaming.Trigger
// Default trigger (runs micro-batch as soon as it can)
df.writeStream
.format("console")
.start();
// ProcessingTime trigger with two-seconds micro-batch interval
df.writeStream
.format("console")
.trigger(Trigger.ProcessingTime("2 seconds"))
.start();
// One-time trigger (Deprecated, encouraged to use Available-now trigger)
df.writeStream
.format("console")
.trigger(Trigger.Once())
.start();
// Available-now trigger
df.writeStream
.format("console")
.trigger(Trigger.AvailableNow())
.start();
// Continuous trigger with one-second checkpointing interval
df.writeStream
.format("console")
.trigger(Trigger.Continuous("1 second"))
.start();# Default trigger (runs micro-batch as soon as it can)
write.stream(df, "console")
# ProcessingTime trigger with two-seconds micro-batch interval
write.stream(df, "console", trigger.processingTime = "2 seconds")
# One-time trigger
write.stream(df, "console", trigger.once = TRUE)
# Continuous trigger is not yet supported管理串流查詢
啟動查詢時建立的 StreamingQuery 物件可用於監控和管理查詢。
query = df.writeStream.format("console").start() # get the query object
query.id() # get the unique identifier of the running query that persists across restarts from checkpoint data
query.runId() # get the unique id of this run of the query, which will be generated at every start/restart
query.name() # get the name of the auto-generated or user-specified name
query.explain() # print detailed explanations of the query
query.stop() # stop the query
query.awaitTermination() # block until query is terminated, with stop() or with error
query.exception() # the exception if the query has been terminated with error
query.recentProgress # a list of the most recent progress updates for this query
query.lastProgress # the most recent progress update of this streaming queryval query = df.writeStream.format("console").start() // get the query object
query.id // get the unique identifier of the running query that persists across restarts from checkpoint data
query.runId // get the unique id of this run of the query, which will be generated at every start/restart
query.name // get the name of the auto-generated or user-specified name
query.explain() // print detailed explanations of the query
query.stop() // stop the query
query.awaitTermination() // block until query is terminated, with stop() or with error
query.exception // the exception if the query has been terminated with error
query.recentProgress // an array of the most recent progress updates for this query
query.lastProgress // the most recent progress update of this streaming queryStreamingQuery query = df.writeStream().format("console").start(); // get the query object
query.id(); // get the unique identifier of the running query that persists across restarts from checkpoint data
query.runId(); // get the unique id of this run of the query, which will be generated at every start/restart
query.name(); // get the name of the auto-generated or user-specified name
query.explain(); // print detailed explanations of the query
query.stop(); // stop the query
query.awaitTermination(); // block until query is terminated, with stop() or with error
query.exception(); // the exception if the query has been terminated with error
query.recentProgress(); // an array of the most recent progress updates for this query
query.lastProgress(); // the most recent progress update of this streaming queryquery <- write.stream(df, "console") # get the query object
queryName(query) # get the name of the auto-generated or user-specified name
explain(query) # print detailed explanations of the query
stopQuery(query) # stop the query
awaitTermination(query) # block until query is terminated, with stop() or with error
lastProgress(query) # the most recent progress update of this streaming query您可以在單一 SparkSession 中啟動任意數量的查詢。它們將全部同時執行,並共享叢集資源。您可以使用 sparkSession.streams() 取得 StreamingQueryManager (Scala/Java/Python 文件),它可用於管理目前正在執行的查詢。
spark = ... # spark session
spark.streams.active # get the list of currently active streaming queries
spark.streams.get(id) # get a query object by its unique id
spark.streams.awaitAnyTermination() # block until any one of them terminatesval spark: SparkSession = ...
spark.streams.active // get the list of currently active streaming queries
spark.streams.get(id) // get a query object by its unique id
spark.streams.awaitAnyTermination() // block until any one of them terminatesSparkSession spark = ...
spark.streams().active(); // get the list of currently active streaming queries
spark.streams().get(id); // get a query object by its unique id
spark.streams().awaitAnyTermination(); // block until any one of them terminatesNot available in R.監控串流查詢
有多種方法可以監控正在執行的串流查詢。您可以使用 Spark 的 Dropwizard Metrics 支援將指標推送到外部系統,或以程式設計方式存取它們。
互動式讀取指標
您可以使用 streamingQuery.lastProgress() 和 streamingQuery.status() 直接取得正在執行查詢的目前狀態和指標。 lastProgress() 會傳回 StreamingQueryProgress 物件,在 Scala 和 Java 中,以及在 Python 中具有相同欄位的字典。它包含串流上次觸發時執行的所有進度資訊,例如:處理了哪些資料、處理率、延遲時間等。還有 streamingQuery.recentProgress,它會傳回陣列,其中包含最近幾次的進度。
此外,streamingQuery.status() 會傳回 StreamingQueryStatus 物件,在 Scala 和 Java 中,以及在 Python 中具有相同欄位的字典。它會提供查詢目前正在執行的資訊,例如:觸發是否已啟動、資料是否正在處理等。
以下是一些範例。
query = ... # a StreamingQuery
print(query.lastProgress)
'''
Will print something like the following.
{u'stateOperators': [], u'eventTime': {u'watermark': u'2016-12-14T18:45:24.873Z'}, u'name': u'MyQuery', u'timestamp': u'2016-12-14T18:45:24.873Z', u'processedRowsPerSecond': 200.0, u'inputRowsPerSecond': 120.0, u'numInputRows': 10, u'sources': [{u'description': u'KafkaSource[Subscribe[topic-0]]', u'endOffset': {u'topic-0': {u'1': 134, u'0': 534, u'3': 21, u'2': 0, u'4': 115}}, u'processedRowsPerSecond': 200.0, u'inputRowsPerSecond': 120.0, u'numInputRows': 10, u'startOffset': {u'topic-0': {u'1': 1, u'0': 1, u'3': 1, u'2': 0, u'4': 1}}}], u'durationMs': {u'getOffset': 2, u'triggerExecution': 3}, u'runId': u'88e2ff94-ede0-45a8-b687-6316fbef529a', u'id': u'ce011fdc-8762-4dcb-84eb-a77333e28109', u'sink': {u'description': u'MemorySink'}}
'''
print(query.status)
'''
Will print something like the following.
{u'message': u'Waiting for data to arrive', u'isTriggerActive': False, u'isDataAvailable': False}
'''val query: StreamingQuery = ...
println(query.lastProgress)
/* Will print something like the following.
{
"id" : "ce011fdc-8762-4dcb-84eb-a77333e28109",
"runId" : "88e2ff94-ede0-45a8-b687-6316fbef529a",
"name" : "MyQuery",
"timestamp" : "2016-12-14T18:45:24.873Z",
"numInputRows" : 10,
"inputRowsPerSecond" : 120.0,
"processedRowsPerSecond" : 200.0,
"durationMs" : {
"triggerExecution" : 3,
"getOffset" : 2
},
"eventTime" : {
"watermark" : "2016-12-14T18:45:24.873Z"
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "KafkaSource[Subscribe[topic-0]]",
"startOffset" : {
"topic-0" : {
"2" : 0,
"4" : 1,
"1" : 1,
"3" : 1,
"0" : 1
}
},
"endOffset" : {
"topic-0" : {
"2" : 0,
"4" : 115,
"1" : 134,
"3" : 21,
"0" : 534
}
},
"numInputRows" : 10,
"inputRowsPerSecond" : 120.0,
"processedRowsPerSecond" : 200.0
} ],
"sink" : {
"description" : "MemorySink"
}
}
*/
println(query.status)
/* Will print something like the following.
{
"message" : "Waiting for data to arrive",
"isDataAvailable" : false,
"isTriggerActive" : false
}
*/StreamingQuery query = ...
System.out.println(query.lastProgress());
/* Will print something like the following.
{
"id" : "ce011fdc-8762-4dcb-84eb-a77333e28109",
"runId" : "88e2ff94-ede0-45a8-b687-6316fbef529a",
"name" : "MyQuery",
"timestamp" : "2016-12-14T18:45:24.873Z",
"numInputRows" : 10,
"inputRowsPerSecond" : 120.0,
"processedRowsPerSecond" : 200.0,
"durationMs" : {
"triggerExecution" : 3,
"getOffset" : 2
},
"eventTime" : {
"watermark" : "2016-12-14T18:45:24.873Z"
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "KafkaSource[Subscribe[topic-0]]",
"startOffset" : {
"topic-0" : {
"2" : 0,
"4" : 1,
"1" : 1,
"3" : 1,
"0" : 1
}
},
"endOffset" : {
"topic-0" : {
"2" : 0,
"4" : 115,
"1" : 134,
"3" : 21,
"0" : 534
}
},
"numInputRows" : 10,
"inputRowsPerSecond" : 120.0,
"processedRowsPerSecond" : 200.0
} ],
"sink" : {
"description" : "MemorySink"
}
}
*/
System.out.println(query.status());
/* Will print something like the following.
{
"message" : "Waiting for data to arrive",
"isDataAvailable" : false,
"isTriggerActive" : false
}
*/query <- ... # a StreamingQuery
lastProgress(query)
'''
Will print something like the following.
{
"id" : "8c57e1ec-94b5-4c99-b100-f694162df0b9",
"runId" : "ae505c5a-a64e-4896-8c28-c7cbaf926f16",
"name" : null,
"timestamp" : "2017-04-26T08:27:28.835Z",
"numInputRows" : 0,
"inputRowsPerSecond" : 0.0,
"processedRowsPerSecond" : 0.0,
"durationMs" : {
"getOffset" : 0,
"triggerExecution" : 1
},
"stateOperators" : [ {
"numRowsTotal" : 4,
"numRowsUpdated" : 0
} ],
"sources" : [ {
"description" : "TextSocketSource[host: localhost, port: 9999]",
"startOffset" : 1,
"endOffset" : 1,
"numInputRows" : 0,
"inputRowsPerSecond" : 0.0,
"processedRowsPerSecond" : 0.0
} ],
"sink" : {
"description" : "org.apache.spark.sql.execution.streaming.ConsoleSink@76b37531"
}
}
'''
status(query)
'''
Will print something like the following.
{
"message" : "Waiting for data to arrive",
"isDataAvailable" : false,
"isTriggerActive" : false
}
'''使用非同步 API 以程式化方式報告指標
您也可以透過附加 StreamingQueryListener (Scala/Java/Python 文件) 來非同步監控與 SparkSession 關聯的所有查詢。一旦您使用 sparkSession.streams.addListener() 附加自訂 StreamingQueryListener 物件,您就會在查詢啟動和停止時,以及在正在執行的查詢中有進度時收到回呼。以下是範例:
spark = ...
class Listener(StreamingQueryListener):
def onQueryStarted(self, event):
print("Query started: " + queryStarted.id)
def onQueryProgress(self, event):
print("Query made progress: " + queryProgress.progress)
def onQueryTerminated(self, event):
print("Query terminated: " + queryTerminated.id)
spark.streams.addListener(Listener())val spark: SparkSession = ...
spark.streams.addListener(new StreamingQueryListener() {
override def onQueryStarted(queryStarted: QueryStartedEvent): Unit = {
println("Query started: " + queryStarted.id)
}
override def onQueryTerminated(queryTerminated: QueryTerminatedEvent): Unit = {
println("Query terminated: " + queryTerminated.id)
}
override def onQueryProgress(queryProgress: QueryProgressEvent): Unit = {
println("Query made progress: " + queryProgress.progress)
}
})SparkSession spark = ...
spark.streams().addListener(new StreamingQueryListener() {
@Override
public void onQueryStarted(QueryStartedEvent queryStarted) {
System.out.println("Query started: " + queryStarted.id());
}
@Override
public void onQueryTerminated(QueryTerminatedEvent queryTerminated) {
System.out.println("Query terminated: " + queryTerminated.id());
}
@Override
public void onQueryProgress(QueryProgressEvent queryProgress) {
System.out.println("Query made progress: " + queryProgress.progress());
}
});Not available in R.使用 Dropwizard 報告指標
Spark 支援使用 Dropwizard 函式庫 報告指標。若要讓結構化串流查詢的指標也能報告,您必須在 SparkSession 中明確啟用組態 spark.sql.streaming.metricsEnabled。
spark.conf.set("spark.sql.streaming.metricsEnabled", "true")
# or
spark.sql("SET spark.sql.streaming.metricsEnabled=true")spark.conf.set("spark.sql.streaming.metricsEnabled", "true")
// or
spark.sql("SET spark.sql.streaming.metricsEnabled=true")spark.conf().set("spark.sql.streaming.metricsEnabled", "true");
// or
spark.sql("SET spark.sql.streaming.metricsEnabled=true");sql("SET spark.sql.streaming.metricsEnabled=true")此組態啟用後在 SparkSession 中啟動的所有查詢,都會透過 Dropwizard 將指標報告給已組態的任何 接收器(例如 Ganglia、Graphite、JMX 等)。
使用檢查點從失敗中復原
在發生故障或故意關閉時,您可以復原前一個查詢的先前進度和狀態,並從中斷處繼續。這是使用檢查點和預寫記錄來完成的。您可以使用檢查點位置來組態查詢,而查詢會將所有進度資訊(例如在每個觸發器中處理的偏移量範圍)和正在執行的聚合(例如 快速範例 中的字數)儲存到檢查點位置。此檢查點位置必須是 HDFS 相容檔案系統中的路徑,並可以在 啟動查詢 時設定為 DataStreamWriter 中的選項。
aggDF \
.writeStream \
.outputMode("complete") \
.option("checkpointLocation", "path/to/HDFS/dir") \
.format("memory") \
.start()aggDF
.writeStream
.outputMode("complete")
.option("checkpointLocation", "path/to/HDFS/dir")
.format("memory")
.start()aggDF
.writeStream()
.outputMode("complete")
.option("checkpointLocation", "path/to/HDFS/dir")
.format("memory")
.start();write.stream(aggDF, "memory", outputMode = "complete", checkpointLocation = "path/to/HDFS/dir")串流查詢變更後的復原語意
從相同的檢查點位置重新啟動時,串流查詢中允許的變更受到限制。以下列出幾種不允許變更的類型,或變更的效果未定義明確。對於所有這些變更
-
術語允許表示您可以執行指定的變更,但其效果的語意是否定義明確則取決於查詢和變更。
-
術語不允許表示您不應該執行指定的變更,因為重新啟動的查詢可能會因無法預測的錯誤而失敗。
sdf表示使用 sparkSession.readStream 產生的串流 DataFrame/Dataset。
變更類型
-
輸入來源的數量或類型(即不同的來源)變更:不允許。
-
輸入來源參數變更:是否允許以及變更的語意是否定義明確,取決於來源和查詢。以下列出幾個範例。
-
允許新增/刪除/修改速率限制:
spark.readStream.format("kafka").option("subscribe", "topic")至spark.readStream.format("kafka").option("subscribe", "topic").option("maxOffsetsPerTrigger", ...) -
通常不允許變更訂閱的主題/檔案,因為結果無法預測:
spark.readStream.format("kafka").option("subscribe", "topic")至spark.readStream.format("kafka").option("subscribe", "newTopic")
-
-
輸出接收器的類型變更:允許在幾個特定接收器組合之間進行變更。這需要逐案驗證。以下列出幾個範例。
-
允許檔案接收器變更為 Kafka 接收器。Kafka 只會看到新資料。
-
不允許 Kafka 接收器變更為檔案接收器。
-
允許 Kafka 接收器變更為 foreach,反之亦然。
-
-
輸出接收器參數的變更:是否允許變更以及變更的語意是否定義明確,取決於接收器和查詢。以下是幾個範例。
-
不允許變更檔案接收器的輸出目錄:
sdf.writeStream.format("parquet").option("path", "/somePath")變更為sdf.writeStream.format("parquet").option("path", "/anotherPath") -
允許變更輸出主題:
sdf.writeStream.format("kafka").option("topic", "someTopic")變更為sdf.writeStream.format("kafka").option("topic", "anotherTopic") -
允許變更使用者定義的 foreach 接收器(也就是
ForeachWriter程式碼),但變更的語意取決於程式碼。
-
-
投影/篩選/類似 map 的運算變更:有些情況允許變更。例如
-
允許新增/刪除篩選條件:
sdf.selectExpr("a")變更為sdf.where(...).selectExpr("a").filter(...)。 -
允許變更投影,但輸出架構相同:
sdf.selectExpr("stringColumn AS json").writeStream變更為sdf.selectExpr("anotherStringColumn AS json").writeStream -
有條件允許變更投影,但輸出架構不同:
sdf.selectExpr("a").writeStream變更為sdf.selectExpr("b").writeStream僅在輸出接收器允許架構從"a"變更為"b"時才允許。
-
-
狀態運算變更:串流查詢中的某些運算需要維護狀態資料,才能持續更新結果。結構化串流會自動將狀態資料檢查點儲存到容錯儲存體(例如 HDFS、AWS S3、Azure Blob 儲存體),並在重新啟動後還原資料。不過,這假設狀態資料的架構在重新啟動時保持不變。這表示在重新啟動時,不允許變更串流查詢的狀態運算(也就是新增、刪除或修改架構)。以下是狀態運算的清單,其架構不應在重新啟動時變更,以確保狀態復原
-
串流聚合:例如
sdf.groupBy("a").agg(...)。不允許變更分組鍵或聚合的數量或類型。 -
串流重複資料刪除:例如
sdf.dropDuplicates("a")。不允許變更重複資料刪除欄的數量或類型。 -
串流與串流聯結:例如
sdf1.join(sdf2, ...)(也就是兩個輸入都使用sparkSession.readStream產生)。不允許變更架構或等值聯結欄。不允許變更聯結類型(外部或內部)。聯結條件的其他變更定義不明確。 -
任意有狀態操作:例如,
sdf.groupByKey(...).mapGroupsWithState(...)或sdf.groupByKey(...).flatMapGroupsWithState(...)。不允許變更使用者定義狀態的架構和逾時類型。允許在使用者定義狀態對應函式中進行任何變更,但變更的語意效果取決於使用者定義的邏輯。如果您真的想要支援狀態架構變更,則可以使用支援架構遷移的編碼/解碼方案,將複雜的狀態資料結構明確編碼/解碼為位元組。例如,如果您將狀態儲存為 Avro 編碼的位元組,則您可以在查詢重新啟動之間自由變更 Avro 狀態架構,因為二進位狀態將始終成功還原。
-
非同步進度追蹤
什麼是?
非同步進度追蹤允許串流查詢非同步地並與微批次中的實際資料處理平行檢查進度,減少與維護偏移量記錄檔和提交記錄檔相關的延遲。
如何運作?
結構化串流依賴於將偏移量持續儲存和管理為查詢處理的進度指標。偏移量管理操作直接影響處理延遲,因為在這些操作完成之前無法進行任何資料處理。非同步進度追蹤使串流查詢能夠檢查進度,而不會受到這些偏移量管理操作的影響。
如何使用?
以下程式碼片段提供如何使用此功能的範例
val stream = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
下表說明此功能的組態和與其相關聯的預設值。
| 選項 | 值 | 預設值 | 說明 |
|---|---|---|---|
| asyncProgressTrackingEnabled | true/false | false | 啟用或停用非同步進度追蹤 |
| asyncProgressTrackingCheckpointIntervalMs | 毫秒 | 1000 | 我們提交偏移量和完成提交的間隔 |
限制
此功能的初始版本具有下列限制
- 非同步進度追蹤僅在使用 Kafka Sink 的無狀態查詢中受支援
- 由於批次的偏移量範圍在發生故障時可能會變更,因此此非同步進度追蹤不會支援完全一次性端對端處理。儘管許多 Sink(例如 Kafka Sink)不支援一次性寫入。
關閉設定
關閉非同步進度追蹤可能會導致擲出以下例外狀況
java.lang.IllegalStateException: batch x doesn't exist
此外,下列錯誤訊息可能會印在驅動程式記錄中
The offset log for batch x doesn't exist, which is required to restart the query from the latest batch x from the offset log. Please ensure there are two subsequent offset logs available for the latest batch via manually deleting the offset file(s). Please also ensure the latest batch for commit log is equal or one batch earlier than the latest batch for offset log.
這是因為在啟用非同步進度追蹤時,架構不會為每個批次檢查進度,就像在不使用非同步進度追蹤時一樣。若要解決此問題,只需重新啟用「asyncProgressTrackingEnabled」,並將「asyncProgressTrackingCheckpointIntervalMs」設為 0,然後執行串流查詢,直到至少處理兩個微批次為止。現在可以安全地停用非同步進度追蹤,且重新啟動查詢應能正常進行。
連續處理
[實驗性質]
連續處理是 Spark 2.3 中引入的一種新的實驗性串流執行模式,可提供低 (~1 毫秒) 端對端延遲,並保證至少一次的容錯能力。將此與預設的微批次處理引擎進行比較,後者可以達到完全一次的保證,但延遲時間最多只能達到 ~100 毫秒。對於某些類型的查詢(如下所述),您可以在不修改應用程式邏輯(即不變更 DataFrame/Dataset 作業)的情況下選擇執行它們的模式。
若要在連續處理模式下執行受支援的查詢,您只需指定一個連續觸發器,並將所需的檢查點間隔作為參數。例如,
spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribe", "topic1") \
.load() \
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)") \
.writeStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("topic", "topic1") \
.trigger(continuous="1 second") \ # only change in query
.start()import org.apache.spark.sql.streaming.Trigger
spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
.trigger(Trigger.Continuous("1 second")) // only change in query
.start()import org.apache.spark.sql.streaming.Trigger;
spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
.trigger(Trigger.Continuous("1 second")) // only change in query
.start();1 秒的檢查點間隔表示連續處理引擎將每秒記錄一次查詢的進度。產生的檢查點採用與微批次引擎相容的格式,因此任何查詢都可以使用任何觸發器重新啟動。例如,以微批次模式啟動的受支援查詢可以在連續模式下重新啟動,反之亦然。請注意,任何時候切換到連續模式,您都將獲得至少一次的容錯保證。
受支援的查詢
截至 Spark 2.4,只有下列類型的查詢在連續處理模式下受支援。
- 作業:連續模式中僅支援類似映射的 Dataset/DataFrame 作業,也就是說,僅支援投影 (
select、map、flatMap、mapPartitions等) 和選取 (where、filter等)。- 支援所有 SQL 函數,但聚合函數除外(因為尚未支援聚合),
current_timestamp()和current_date()(使用時間的確定性運算具有挑戰性)。
- 支援所有 SQL 函數,但聚合函數除外(因為尚未支援聚合),
- 來源:
- Kafka 來源:支援所有選項。
- 速率來源:適合測試。連續模式中支援的選項只有
numPartitions和rowsPerSecond。
- 接收器:
- Kafka 接收器:支援所有選項。
- 記憶體接收器:適合除錯。
- 主控台接收器:適合除錯。支援所有選項。請注意,主控台會印出您在連續觸發器中指定的每個檢查點間隔。
請參閱 輸入來源 和 輸出接收器 部分,以取得更多詳細資訊。雖然主控台接收器適合測試,但端對端低延遲處理最適合使用 Kafka 作為來源和接收器,因為這允許引擎處理資料,並在輸入資料在輸入主題中可用後幾毫秒內在輸出主題中提供結果。
注意事項
- 連續處理引擎會啟動多個長時間執行的工作,這些工作會持續從來源讀取資料、處理資料,並持續寫入接收器。查詢所需的任務數目取決於查詢可以並行從來源讀取多少個分割區。因此,在啟動連續處理查詢之前,您必須確保叢集中有足夠的核心來並行執行所有任務。例如,如果您從具有 10 個分割區的 Kafka 主題讀取,則叢集必須至少有 10 個核心才能讓查詢進行處理。
- 停止連續處理串流可能會產生虛假的任務終止警告。這些警告可以安全地忽略。
- 目前沒有自動重試失敗的任務。任何失敗都將導致查詢停止,並且需要從檢查點手動重新啟動查詢。
其他資訊
注意事項
- 查詢執行後,有幾個組態無法修改。若要變更這些組態,請捨棄檢查點並啟動新的查詢。這些組態包括
spark.sql.shuffle.partitions- 這是由於狀態的實體分割:狀態會透過將雜湊函數套用到金鑰來進行分割,因此狀態的分割區數目不應變更。
- 如果您想為有狀態操作執行較少的任務,
coalesce將有助於避免不必要的重新分割。- 在
coalesce之後,(減少的)任務數目將會保留,除非發生另一個重新分割。
- 在
spark.sql.streaming.stateStore.providerClass:若要正確讀取查詢的先前狀態,狀態儲存提供者的類別不應變更。spark.sql.streaming.multipleWatermarkPolicy:修改此設定會導致查詢包含多個浮水印時浮水印值不一致,因此政策不應變更。
進一步閱讀
- 查看並執行 Scala/Java/Python/R 範例。
- 說明說明如何執行 Spark 範例
- 在 結構化串流 Kafka 整合指南中閱讀與 Kafka 整合的相關資訊
- 在 Spark SQL 程式設計指南中閱讀有關在 DataFrames/Datasets 中使用的更多詳細資訊
- 第三方部落格文章
演講
- 2017 年 Spark 峰會歐洲
- Apache Spark 中使用結構化串流進行簡單、可擴充、容錯的串流處理 - 第 1 部分投影片/影片、第 2 部分投影片/影片
- 深入探討結構化串流中的有狀態串流處理 - 投影片/影片
- 2016 年 Spark 峰會
- 深入探討結構化串流 - 投影片/影片
遷移指南
遷移指南現已封存 在此頁面。