Web UI
Apache Spark 提供一組 Web 使用者介面 (UI),您可以使用這些介面來監控 Spark 集群的狀態和資源消耗。
目錄
工作索引標籤
工作標籤顯示 Spark 應用程式中所有工作的摘要頁面,以及每個工作的詳細資料頁面。摘要頁面顯示高階資訊,例如所有工作的狀態、持續時間和進度,以及整體事件時間軸。當您在摘要頁面上按一下某個工作時,您會看到該工作的詳細資料頁面。詳細資料頁面進一步顯示事件時間軸、DAG 視覺化和工作的各個階段。
此區段中顯示的資訊為
- 使用者:目前的 Spark 使用者
- 總上線時間:Spark 應用程式啟動以來的時間
- 排程模式:請參閱 工作排程
- 每個狀態的工作數目:已啟用、已完成、已失敗

- 事件時間軸:按時間順序顯示與執行器 (已新增、已移除) 和工作相關的事件

- 依狀態分組的工作詳細資料:顯示工作的詳細資訊,包括工作 ID、說明 (附有連結至詳細工作頁面)、提交時間、持續時間、階段摘要和工作進度列

當您按一下特定工作時,您可以看到此工作的詳細資訊。
工作詳細資料
此頁面顯示由工作 ID 識別的特定工作的詳細資料。
- 工作狀態:(執行中、已成功、已失敗)
- 每個狀態的階段數目 (已啟用、待處理、已完成、已略過、已失敗)
- 關聯的 SQL 查詢:連結至此工作的 SQL 標籤
- 事件時間軸:按時間順序顯示與執行器 (已新增、已移除) 和工作階段相關的事件

- DAG 視覺化:此工作的有向非循環圖形視覺化表示,其中頂點代表 RDD 或資料框,而邊緣代表要套用至 RDD 的作業。
- DAG 視覺化範例,針對
sc.parallelize(1 to 100).toDF.count()

- 階段清單 (依狀態分組,包括已啟用、待處理、已完成、已略過和已失敗)
- 階段 ID
- 階段說明
- 已提交時間戳記
- 階段持續時間
- 工作進度列
- 輸入:此階段從儲存體讀取的位元組
- 輸出:此階段寫入儲存體的位元組
- 洗牌讀取:總洗牌位元組和讀取的記錄,包括本地讀取的資料和從遠端執行器讀取的資料
- Shuffle 寫入:位元組和記錄寫入磁碟,以便在未來階段的 Shuffle 中讀取

階段索引標籤
「階段」標籤會顯示一個摘要頁面,顯示 Spark 應用程式中所有階段的所有工作目前的狀態。
頁面開頭是摘要,其中包含依狀態計算的所有階段(已啟動、待處理、已完成、已略過和已失敗)


之後是依狀態(已啟動、待處理、已完成、已略過、已失敗)顯示的階段詳細資料。在已啟動階段中,可以使用終止連結終止階段。只有在已失敗階段中,才會顯示失敗原因。可以按一下說明來存取工作詳細資料。

階段詳細資料
階段詳細資料頁面會從資訊開始,例如所有工作的所有時間、區域性層級摘要、Shuffle 讀取大小/記錄 和相關工作 ID。

此階段的非循環有向圖 (DAG) 也有視覺化表示,其中頂點代表 RDD 或資料框,而邊緣代表要套用的作業。節點會依 DAG 視覺化中的作業範圍進行分組,並標示作業範圍名稱(批次掃描、WholeStageCodegen、交換等)。特別是,Whole Stage Code Generation 作業也會註解有程式碼產生 ID。對於屬於 Spark 資料框或 SQL 執行的階段,這允許將階段執行詳細資料交叉參照到 Web UI SQL 標籤頁面中的相關詳細資料,其中會報告 SQL 計畫圖形和執行計畫。

所有工作的摘要指標會以表格和時間軸表示。
- 工作反序列化時間
- 工作持續時間.
- GC 時間是 JVM 垃圾回收總時間。
- 結果序列化時間是在將工作結果序列化到執行器上然後傳回驅動程式之前所花費的時間。
- 取得結果時間是驅動程式花費在從工作人員擷取工作結果的時間。
- 排程延遲是工作等待排程執行的時間。
- 執行記憶體使用量高峰是在 Shuffle、聚合和聯結期間建立的內部資料結構使用的最大記憶體。
- Shuffle 讀取大小/記錄。讀取的 Shuffle 總位元組,包括在本地讀取的資料和從遠端執行器讀取的資料。
- Shuffle 讀取擷取等待時間是工作花費在封鎖等待從遠端機器讀取 Shuffle 資料的時間。
- 混排遠端讀取是從遠端執行器讀取的總混排位元組。
- 混排寫入時間是任務花費在寫入混排資料的時間。
- 混排溢出(記憶體)是記憶體中混排資料的非序列化形式的大小。
- 混排溢出(磁碟)是磁碟上資料的序列化形式的大小。

依執行器彙總的指標會顯示依執行器彙總的相同資訊。

累加器是一種共用變數。它提供一個可變變數,可以在各種轉換內更新。可以建立有或沒有名稱的累加器,但只會顯示有名稱的累加器。

任務詳細資料基本上包含與摘要區段中相同的資訊,但會依任務詳細說明。它也包含檢閱記錄的連結,以及如果任務因任何原因失敗,則包含任務嘗試次數。如果有命名累加器,則可以在此看到每個任務結束時的累加器值。

儲存空間索引標籤
儲存標籤會顯示應用程式中(如果有)的持續 RDD 和資料框。摘要頁面會顯示所有 RDD 的儲存層級、大小和分割,而詳細資料頁面會顯示 RDD 或資料框中所有分割的大小和使用中的執行器。
scala> import org.apache.spark.storage.StorageLevel._
import org.apache.spark.storage.StorageLevel._
scala> val rdd = sc.range(0, 100, 1, 5).setName("rdd")
rdd: org.apache.spark.rdd.RDD[Long] = rdd MapPartitionsRDD[1] at range at <console>:27
scala> rdd.persist(MEMORY_ONLY_SER)
res0: rdd.type = rdd MapPartitionsRDD[1] at range at <console>:27
scala> rdd.count
res1: Long = 100
scala> val df = Seq((1, "andy"), (2, "bob"), (2, "andy")).toDF("count", "name")
df: org.apache.spark.sql.DataFrame = [count: int, name: string]
scala> df.persist(DISK_ONLY)
res2: df.type = [count: int, name: string]
scala> df.count
res3: Long = 3

在執行以上範例後,我們可以在儲存標籤中找到兩個 RDD。會提供基本資訊,例如儲存層級、分割數和記憶體開銷。請注意,在實體化之前,不會在標籤中顯示新持續的 RDD 或資料框。若要監控特定 RDD 或資料框,請確定已觸發動作操作。

您可以按一下 RDD 名稱「rdd」以取得資料持續性的詳細資料,例如叢集上的資料分佈。
環境索引標籤
環境標籤會顯示不同環境和組態變數的值,包括 JVM、Spark 和系統屬性。

此環境頁面包含五個部分。這是檢查您的屬性是否已正確設定的實用地方。第一部分「執行時間資訊」僅包含執行時間屬性,例如 Java 和 Scala 的版本。第二部分「Spark 屬性」列出應用程式屬性,例如「spark.app.name」和「spark.driver.memory」。

按一下「Hadoop 屬性」連結會顯示與 Hadoop 和 YARN 相關的屬性。請注意,例如「spark.hadoop.*」等屬性不會顯示在此部分,而會顯示在「Spark 屬性」中。

「系統屬性」會顯示 JVM 的更多詳細資料。

最後一部分「類別路徑項目」會列出從不同來源載入的類別,這對於解決類別衝突非常實用。
執行器標籤
「執行器」標籤會顯示為應用程式建立的執行器的摘要資訊,包括記憶體和磁碟使用量,以及工作和洗牌資訊。「儲存記憶體」欄會顯示用於快取資料的記憶體使用量和保留量。

「執行器」標籤不僅提供資源資訊(每個執行器使用的記憶體、磁碟和核心數量),還提供效能資訊(GC 時間和洗牌資訊)。

按一下執行器 0 的「stderr」連結會在其主控台中顯示詳細的標準錯誤記錄。

按一下執行器 0 的「執行緒傾印」連結會顯示執行器 0 上 JVM 的執行緒傾印,這對於效能分析非常實用。
SQL 標籤
如果應用程式執行 Spark SQL 查詢,「SQL」標籤會顯示資訊,例如查詢的持續時間、工作,以及實體和邏輯計畫。我們在此包含一個基本範例來說明此標籤
scala> val df = Seq((1, "andy"), (2, "bob"), (2, "andy")).toDF("count", "name")
df: org.apache.spark.sql.DataFrame = [count: int, name: string]
scala> df.count
res0: Long = 3
scala> df.createGlobalTempView("df")
scala> spark.sql("select name,sum(count) from global_temp.df group by name").show
+----+----------+
|name|sum(count)|
+----+----------+
|andy| 3|
| bob| 2|
+----+----------+

現在,上述三個資料框/SQL 運算子會顯示在清單中。如果我們按一下最後一個查詢的「在 <主控台> 中顯示:24」連結,我們將會看到查詢執行的 DAG 和詳細資料。

查詢詳細資料頁面會顯示有關查詢執行時間、持續時間、相關工作的清單,以及查詢執行 DAG 的資訊。第一個區塊「WholeStageCodegen (1)」會將多個運算子(「LocalTableScan」和「HashAggregate」)編譯成單一 Java 函數以改善效能,而區塊中會列出列數和溢出大小等指標。「(1)」是區塊名稱中的程式碼產生 ID。第二個區塊「Exchange」會顯示洗牌交換的指標,包括已寫入的洗牌記錄數、總資料大小等。

按一下底部的「詳細資料」連結會顯示邏輯計畫和實體計畫,說明 Spark 如何剖析、分析、最佳化和執行查詢。實體計畫中受全階段程式碼產生最佳化影響的步驟會加上星號,後接程式碼產生 ID,例如:「*(1) LocalTableScan」
SQL 指標
SQL 運算子的指標顯示在實體運算子區塊中。當我們想要深入了解每個運算子的執行細節時,SQL 指標會很有用。例如,在 Filter 運算子之後,「輸出列數」可以回答輸出多少列,「Exchange 運算子中的「總寫入交換位元組」顯示交換寫入的位元組數。
以下是 SQL 指標清單
| SQL 指標 | 意義 | 運算子 |
|---|---|---|
輸出列數 | 運算子的輸出列數 | 聚集運算子、Join 運算子、Sample、Range、Scan 運算子、Filter 等。 |
資料大小 | 運算子的廣播/交換/收集資料大小 | BroadcastExchange、ShuffleExchange、Subquery |
收集時間 | 花在收集資料上的時間 | BroadcastExchange、Subquery |
掃描時間 | 花在掃描資料上的時間 | ColumnarBatchScan、FileSourceScan |
元資料時間 | 花在取得元資料(例如分割區數目、檔案數目)上的時間 | FileSourceScan |
寫入交換位元組 | 寫入的位元組數目 | CollectLimit、TakeOrderedAndProject、ShuffleExchange |
寫入交換記錄 | 寫入的記錄數目 | CollectLimit、TakeOrderedAndProject、ShuffleExchange |
交換寫入時間 | 花在交換寫入上的時間 | CollectLimit、TakeOrderedAndProject、ShuffleExchange |
讀取遠端區塊 | 遠端讀取的區塊數目 | CollectLimit、TakeOrderedAndProject、ShuffleExchange |
讀取遠端位元組 | 遠端讀取的位元組數目 | CollectLimit、TakeOrderedAndProject、ShuffleExchange |
讀取遠端位元組至磁碟 | 從遠端讀取至本機磁碟的位元組數目 | CollectLimit、TakeOrderedAndProject、ShuffleExchange |
讀取本機區塊 | 本機讀取的區塊數目 | CollectLimit、TakeOrderedAndProject、ShuffleExchange |
讀取本機位元組 | 本機讀取的位元組數目 | CollectLimit、TakeOrderedAndProject、ShuffleExchange |
擷取等待時間 | 花在擷取資料(本機和遠端)上的時間 | CollectLimit、TakeOrderedAndProject、ShuffleExchange |
讀取記錄 | 讀取記錄的數目 | CollectLimit、TakeOrderedAndProject、ShuffleExchange |
排序時間 | 花在排序上的時間 | 排序 |
記憶體使用高峰 | 運算子中記憶體使用的高峰 | 排序、HashAggregate |
溢位大小 | 運算子中從記憶體溢位至磁碟的位元組數目 | 排序、HashAggregate |
聚集建置時間 | 花在聚集上的時間 | HashAggregate、ObjectHashAggregate |
平均雜湊探測儲存區清單迭代次數 | 聚合期間每次查詢的平均儲存區清單迭代次數 | HashAggregate |
建置側資料大小 | 已建置雜湊映射的大小 | ShuffledHashJoin |
建置雜湊映射的時間 | 建置雜湊映射所花費的時間 | ShuffledHashJoin |
工作提交時間 | 寫入成功後提交工作輸出的所花費時間 | 檔案型資料表的任何寫入作業 |
工作提交時間 | 寫入成功後提交工作輸出的所花費時間 | 檔案型資料表的任何寫入作業 |
傳送至 Python 工作人員的資料 | 傳送至 Python 工作人員的序列化資料位元組數 | ArrowEvalPython、AggregateInPandas、BatchEvalPython、FlatMapGroupsInPandas、FlatMapsCoGroupsInPandas、FlatMapsCoGroupsInPandasWithState、MapInPandas、PythonMapInArrow、WindowsInPandas |
從 Python 工作人員傳回的資料 | 從 Python 工作人員接收到的序列化資料位元組數 | ArrowEvalPython、AggregateInPandas、BatchEvalPython、FlatMapGroupsInPandas、FlatMapsCoGroupsInPandas、FlatMapsCoGroupsInPandasWithState、MapInPandas、PythonMapInArrow、WindowsInPandas |
結構化串流標籤
在微批次模式下執行結構化串流工作時,結構化串流索引標籤將顯示在 Web UI 上。概觀頁面會顯示正在執行和已完成查詢的一些簡要統計資料。此外,您也可以查看失敗查詢的最新例外狀況。如需詳細統計資料,請按表格中的「執行 ID」。

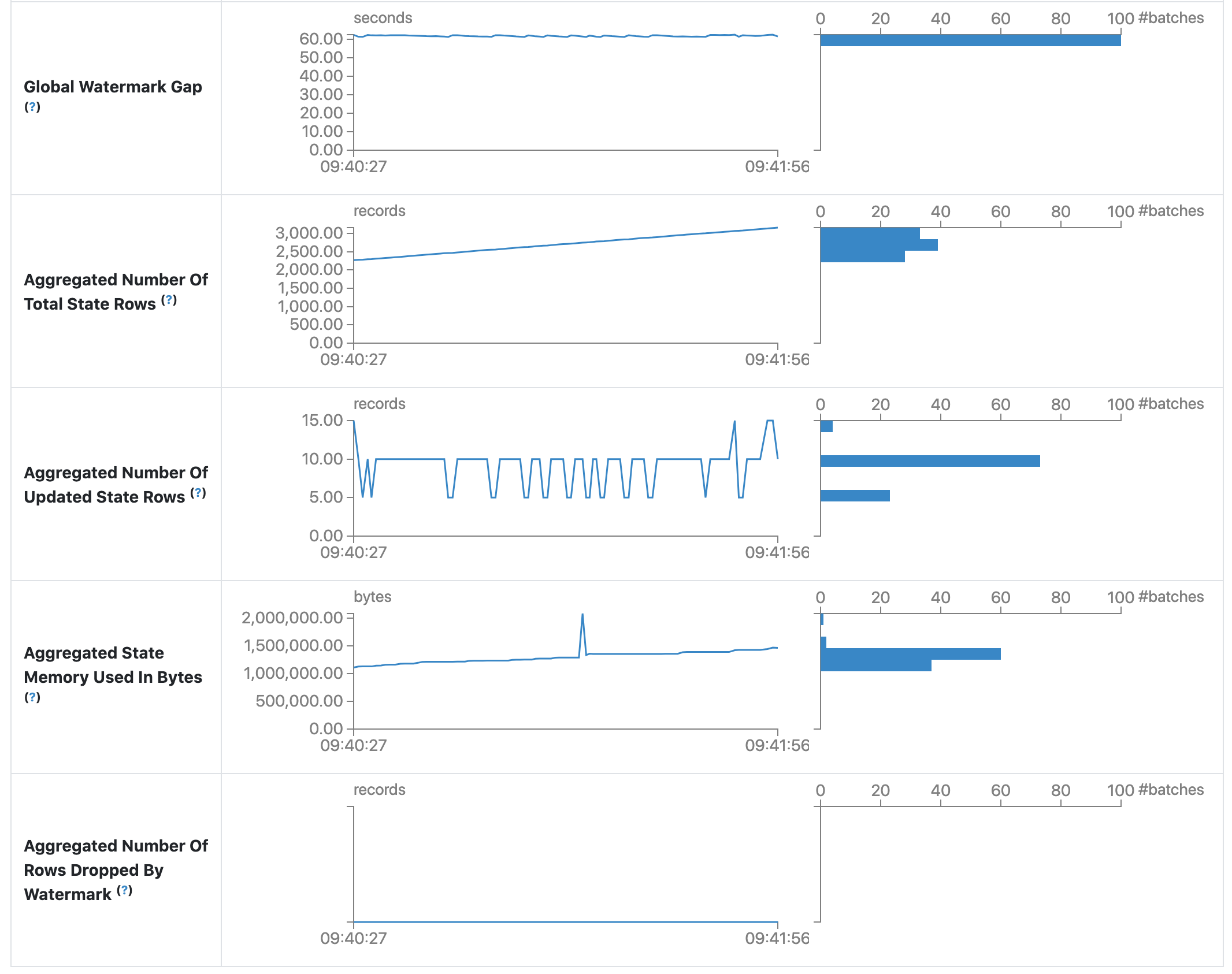
統計資料頁面會顯示一些有用的指標,讓您深入了解串流查詢的狀態。目前,它包含下列指標。
- 輸入率。資料抵達的總計(所有來源)率。
- 處理率。Spark 處理資料的總計(所有來源)率。
- 輸入列。在觸發器中處理的記錄總計(所有來源)。
- 批次持續時間。每個批次的處理持續時間。
- 作業持續時間。執行各種作業所花費的時間(以毫秒為單位)。追蹤的作業如下所列。
- addBatch:從來源讀取微批次的輸入資料、處理資料並將批次的輸出寫入接收器所花費的時間。這應佔用微批次的大部分時間。
- getBatch:準備邏輯查詢以從來源讀取目前微批次的輸入所花費的時間。
- latestOffset 和 getOffset:查詢此來源可用的最大偏移量所花費的時間。
- queryPlanning:產生執行計畫所花費的時間。
- walCommit:寫入偏移量至元資料記錄檔所需時間。
- 全域浮水印間隔。批次的時間戳記與批次的全域浮水印之間的間隔。
- 總狀態列的彙總數量。總狀態列的彙總數量。
- 已更新狀態列的彙總數量。已更新狀態列的彙總數量。
- 以位元組為單位的彙總狀態記憶體使用量。以位元組為單位的彙總狀態記憶體使用量。
- 由浮水印捨棄的狀態列彙總數量。由浮水印捨棄的狀態列彙總數量。
作為早期版本,統計資料頁面仍處於開發階段,並將在未來版本中進行改善。
串流 (DStreams) 標籤
如果應用程式使用 DStream API 搭配 Spark Streaming,網路 UI 會包含一個串流標籤。此標籤會顯示資料串流中每個微批次的排程延遲和處理時間,這對於解決串流應用程式的問題很有用。
JDBC/ODBC 伺服器標籤
當 Spark 以 分散式 SQL 引擎 執行時,我們可以看到這個標籤。它會顯示有關工作階段和已提交 SQL 作業的資訊。
此頁面的第一個區段會顯示 JDBC/ODBC 伺服器的概括資訊:開始時間和正常執行時間。

第二個區段包含有關活動和已完成工作階段的資訊。
- 連線的使用者和IP。
- 工作階段 ID 連結可存取工作階段資訊。
- 工作階段的開始時間、結束時間和持續時間。
- 總執行次數是在此工作階段中提交的作業數量。

第三個區段包含已提交作業的 SQL 統計資料。
- 提交作業的使用者。
- 作業 ID 連結至 作業標籤。
- 將所有作業分組在一起的查詢群組 ID。應用程式可以使用此群組 ID 取消所有正在執行的作業。
- 作業的開始時間。
- 執行結束時間,在擷取結果之前。
- 擷取結果後的作業關閉時間。
- 執行時間是結束時間和開始時間之間的差異。
- 持續時間是關閉時間和開始時間之間的差異。
- 陳述式是正在執行的操作。
- 處理的狀態。
- 已開始,第一個狀態,當處理開始時。
- 已編譯,已產生執行計畫。
- 已失敗,當執行失敗或以錯誤結束時的最後狀態。
- 已取消,當執行被取消時的最後狀態。
- 已完成處理並正在等待擷取結果。
- 已關閉,當用戶端關閉陳述式時的最後狀態。
- 執行計畫的詳細資料,包括已分析的邏輯計畫、已分析的邏輯計畫、已最佳化的邏輯計畫和實體計畫或 SQL 陳述式中的錯誤。
