測試涵蓋範圍
Apache Spark 社群使用各種資源來維護社群測試涵蓋範圍。
GitHub Actions
GitHub Actions 在 Ubuntu 22.04 上提供下列功能。
Apache Spark 4
- Scala 2.13 SBT 建置,搭配 Java 17
- Scala 2.13 Maven 建置,搭配 Java 17/21
- Java/Scala/Python/R 單元測試,搭配 Java 17/Scala 2.13/SBT
- TPC-DS 基準測試,縮放係數為 1
- JDBC Docker 整合測試
- Kubernetes 整合測試
- 每日 Java/Scala/Python/R 單元測試,搭配 Java 21 和 Scala 2.13/SBT
Apache Spark 3
- Scala 2.12 SBT 建置,搭配 Java 8
- Scala 2.12 Maven 建置,搭配 Java 11/17
- Java/Scala/Python/R 單元測試,搭配 Java 8/Scala 2.12/SBT
- Kubernetes 整合測試
- 每日 Java/Scala/Python/R 單元測試,搭配 Java 8 和 Scala 2.13/SBT
- 每日 JDBC Docker 整合測試,搭配 Java 8 和 Scala 2.13/SBT
- 每日 TPC-DS 基準測試,搭配 Java 8 和 Scala 2.12/SBT,縮放係數為 1
AppVeyor
AppVeyor 在 Windows 上提供下列功能。
- R 單元測試,搭配 Java 17/Scala 2.13/SBT
Scaleway
Scaleway 在 MacOS 和 Apple Silicon 上提供下列功能。
- Java/Scala/Python/R 單元測試,搭配 Java 17/Scala 2.12/SBT
- K8s 整合測試(待定)
實用的開發人員工具
縮短建置時間
SBT:避免重新建立組建 JAR
Spark 的預設建置策略是組建一個包含所有相依項的 jar。在執行反覆開發時,這可能會很麻煩。在本地開發時,可以建立一個包含所有 Spark 相依項的組建 jar,然後在進行變更時只重新封裝 Spark 本身。
$ build/sbt clean package
$ ./bin/spark-shell
$ export SPARK_PREPEND_CLASSES=true
$ ./bin/spark-shell # Now it's using compiled classes
# ... do some local development ... #
$ build/sbt compile
$ unset SPARK_PREPEND_CLASSES
$ ./bin/spark-shell
# You can also use ~ to let sbt do incremental builds on file changes without running a new sbt session every time
$ build/sbt ~compile
個別建置子模組
例如,您可以使用下列方式建置 Spark Core 模組
$ # sbt
$ build/sbt
> project core
> package
$ # or you can build the spark-core module with sbt directly using:
$ build/sbt core/package
$ # Maven
$ build/mvn package -DskipTests -pl core
執行個別測試
在本地開發時,通常很方便執行單一測試或少數測試,而不是執行整個測試套件。
使用 SBT 進行測試
執行個別測試最快速的方法是使用 sbt 主控台。最快速的方法是保持 sbt 主控台開啟,並使用它在需要時重新執行測試。例如,要執行特定專案中的所有測試,例如 core
$ build/sbt
> project core
> test
您可以使用 testOnly 指令執行單一測試套件。例如,要執行 DAGSchedulerSuite
> testOnly org.apache.spark.scheduler.DAGSchedulerSuite
testOnly 指令接受萬用字元;例如,您也可以使用下列方式執行 DAGSchedulerSuite
> testOnly *DAGSchedulerSuite
或者,您可以執行排程器套件中的所有測試
> testOnly org.apache.spark.scheduler.*
如果您只想在 DAGSchedulerSuite 中執行單一測試,例如,名稱中包含「SPARK-12345」的測試,您可以在 sbt 主控台中執行下列指令
> testOnly *DAGSchedulerSuite -- -z "SPARK-12345"
如果您願意,您可以在命令列執行所有這些指令(但這會比使用開啟的主控台執行測試慢)。為執行此操作,您需要使用引號將 testOnly 和後續引數括起來
$ build/sbt "core/testOnly *DAGSchedulerSuite -- -z SPARK-12345"
有關如何使用 sbt 執行個別測試的更多資訊,請參閱 sbt 文件。
使用 Maven 進行測試
使用 Maven 時,您可以使用 -DwildcardSuites 旗標執行個別 Scala 測試
build/mvn -Dtest=none -DwildcardSuites=org.apache.spark.scheduler.DAGSchedulerSuite test
您需要 -Dtest=none 以避免執行 Java 測試。有關 ScalaTest Maven 外掛程式,請參閱 ScalaTest 文件。
要執行個別 Java 測試,您可以使用 -Dtest 旗標
build/mvn test -DwildcardSuites=none -Dtest=org.apache.spark.streaming.JavaAPISuite test
測試 PySpark
要執行個別 PySpark 測試,您可以在 python 目錄下使用 run-tests 腳本。測試案例位於每個 PySpark 套件下的 tests 套件中。請注意,如果您在 Apache Spark 中對 Scala 或 Python 端進行一些變更,則您需要在執行 PySpark 測試之前手動重新建置 Apache Spark,才能套用變更。執行 PySpark 測試腳本不會自動建置它。
此外,請注意,在 macOS High Serria+ 上使用 PySpark 有個持續進行的問題。 OBJC_DISABLE_INITIALIZE_FORK_SAFETY 應設定為 YES 才能執行某些測試。請參閱 PySpark 問題 和 Python 問題 以取得更多詳細資訊。
要在特定模組中執行測試案例
$ python/run-tests --testnames pyspark.sql.tests.test_arrow
要在特定類別中執行測試案例
$ python/run-tests --testnames 'pyspark.sql.tests.test_arrow ArrowTests'
在特定類別中執行單一測試案例
$ python/run-tests --testnames 'pyspark.sql.tests.test_arrow ArrowTests.test_null_conversion'
您也可以在特定模組中執行 doctest
$ python/run-tests --testnames pyspark.sql.dataframe
最後,在相同位置中還有另一個稱為 run-tests-with-coverage 的指令碼,它會為 PySpark 測試產生涵蓋率報告。它接受與 run-tests 相同的參數。
$ python/run-tests-with-coverage --testnames pyspark.sql.tests.test_arrow --python-executables=python
...
Name Stmts Miss Branch BrPart Cover
-------------------------------------------------------------------
pyspark/__init__.py 42 4 8 2 84%
pyspark/_globals.py 16 3 4 2 75%
...
Generating HTML files for PySpark coverage under /.../spark/python/test_coverage/htmlcov
您可以在 /.../spark/python/test_coverage/htmlcov 下的 HTML 中以視覺方式查看涵蓋率報告。
請透過 python/run-tests[-with-coverage] --help 查看其他可用選項。
測試 K8S
儘管 GitHub Actions 提供 K8s 單元測試和整合測試涵蓋率,您可以在本地執行它。例如,Volcano 批次排程器整合測試應手動完成。有關詳細資訊,請參閱整合測試文件。
https://github.com/apache/spark/blob/master/resource-managers/kubernetes/integration-tests/README.md
執行 Docker 整合測試
Docker 整合測試由 GitHub Actions 涵蓋。但是,您可以在本地執行它以加速開發和測試。有關詳細資訊,請參閱 Docker 整合測試文件。
使用 GitHub Actions 工作流程進行測試
Apache Spark 利用 GitHub Actions,它能進行持續整合和廣泛的自動化。Apache Spark 儲存庫提供多個 GitHub Actions 工作流程,供開發人員在建立 pull request 之前執行。
在您分岔的儲存庫中執行基準測試
Apache Spark 儲存庫提供一個簡單的方法,可以在 GitHub Actions 中執行基準測試。當您在 pull request 中更新基準測試結果時,建議使用 GitHub Actions 在盡可能相同的環境中執行基準測試並產生結果。
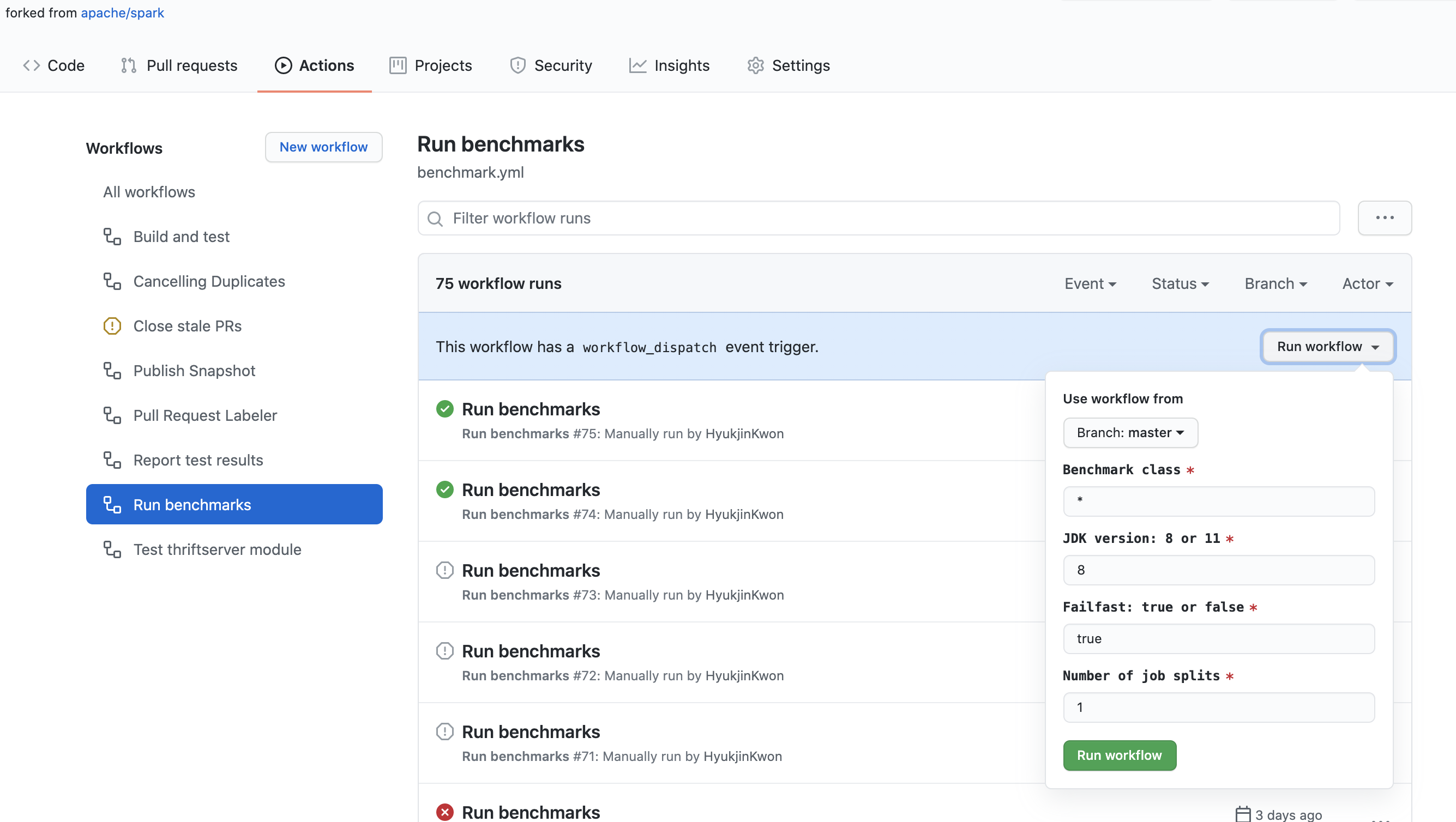
- 在您分岔的儲存庫中按一下「動作」標籤。
- 在「所有工作流程」清單中選取「執行基準測試」工作流程。
- 按一下「執行工作流程」按鈕,並適當地輸入欄位,如下所示
- 基準測試類別:您希望執行的基準測試類別。它允許使用 glob 模式。例如,
org.apache.spark.sql.*。 - JDK 版本:您要使用其執行基準測試的 Java 版本。例如,
11。 - 快速失敗:表示當基準測試失敗時,您是否要停止基準測試和工作流程。當
true時,它會立即失敗。當false時,無論是否失敗,它都會執行所有基準測試。 - 工作分割數量:它將基準工作分割成指定的數量,並平行執行。這對於解決 GitHub Actions 中工作流程和工作的時間限制特別有用。
- 基準測試類別:您希望執行的基準測試類別。它允許使用 glob 模式。例如,
- 完成「執行基準測試」工作流程後,按一下工作流程並在「成品」下載基準測試結果。
- 前往 Apache Spark 儲存庫的根目錄,並解壓縮或解壓縮已下載的檔案,這將更新基準測試結果,並適當定位要更新的檔案。
ScalaTest 問題
如果執行 ScalaTest 時發生下列錯誤
An internal error occurred during: "Launching XYZSuite.scala".
java.lang.NullPointerException
這是因為類別路徑中的 Scala 函式庫不正確。要修正,請
- 右鍵按一下專案
- 選取
建置路徑 | 設定建置路徑 新增函式庫 | Scala 函式庫- 移除
scala-library-2.10.4.jar - lib_managed\jars
如果發生「找不到 Web UI 的資源路徑:org/apache/spark/ui/static」,這是因為類別路徑問題(某些類別可能尚未編譯)。要修正這個問題,只要從命令列執行測試就足夠了
build/sbt "testOnly org.apache.spark.rdd.SortingSuite"
二進位相容性
為了確保二進位相容性,Spark 使用 MiMa。
確保二進位相容性
在處理問題時,在開啟拉取請求之前,最好先檢查變更是否不會造成二進位不相容。您
可以執行下列指令來執行此動作
$ dev/mima
MiMa 回報的二進位不相容可能如下所示
[error] method this(org.apache.spark.sql.Dataset)Unit in class org.apache.spark.SomeClass does not have a correspondent in current version
[error] filter with: ProblemFilters.exclude[DirectMissingMethodProblem]("org.apache.spark.SomeClass.this")
解決二進位不相容
如果您認為您的二進位不相容是合理的,或是 MiMa 回報了錯誤的正向結果(例如,回報的二進位不相容是關於非使用者介面 API),您可以透過在 project/MimaExcludes.scala 中新增排除項來過濾它們,其中包含 MiMa 回報建議的內容,以及包含您正在處理的問題的 JIRA 編號及其標題的註解。
對於上述問題,我們可能會新增下列內容
// [SPARK-zz][CORE] Fix an issue
ProblemFilters.exclude[DirectMissingMethodProblem]("org.apache.spark.SomeClass.this")否則,您必須在開啟或更新拉取請求之前解決這些不相容。通常,MiMa 回報的問題不言自明,而且與您必須新增回來的遺失成員(方法或欄位)有關,以維持二進位相容性。
查看拉取請求
Git 提供一種機制,可以將遠端拉取要求擷取到您自己的本機儲存庫。在檢閱程式碼或在本地測試修補程式時,這會很有用。如果您尚未複製 Spark Git 儲存庫,請使用下列命令
$ git clone https://github.com/apache/spark.git
$ cd spark
若要啟用此功能,您需要設定 git 遠端儲存庫以擷取拉取要求資料。請透過修改 Spark 目錄內的 .git/config 檔案來執行此動作。如果您將遠端儲存庫命名為其他名稱,則其名稱可能不是「origin」
[remote "origin"]
url = git@github.com:apache/spark.git
fetch = +refs/heads/*:refs/remotes/origin/*
fetch = +refs/pull/*/head:refs/remotes/origin/pr/* # Add this line
執行此動作後,您可以擷取遠端拉取要求
# Fetch remote pull requests
$ git fetch origin
# Checkout a remote pull request
$ git checkout origin/pr/112
# Create a local branch from a remote pull request
$ git checkout origin/pr/112 -b new-branch
產生相依關係圖
$ # sbt
$ build/sbt dependencyTree
$ # Maven
$ build/mvn -DskipTests install
$ build/mvn dependency:tree
整理匯入
您可以使用 Aaron Davidson 的 IntelliJ 匯入整理器 來協助您整理程式碼中的匯入。可以設定其與樣式指南中的匯入順序相符。
格式化程式碼
若要格式化 Scala 程式碼,請在提交 PR 之前執行下列命令
$ ./dev/scalafmt
預設情況下,此指令碼會格式化與 git master 不同的檔案。如需更多資訊,請參閱 scalafmt 文件,但請使用現有的指令碼,而非 scalafmt 的本地安裝版本。
IDE 設定
IntelliJ
雖然許多 Spark 開發人員在命令列上使用 SBT 或 Maven,但我們最常使用的 IDE 是 IntelliJ IDEA。您可以免費取得社群版本(Apache 提交者可以取得免費的 IntelliJ Ultimate Edition 授權),並從 喜好設定 > 外掛程式 安裝 JetBrains Scala 外掛程式。
若要為 IntelliJ 建立 Spark 專案
- 下載 IntelliJ 並安裝 適用於 IntelliJ 的 Scala 外掛程式。
- 前往
檔案 -> 匯入專案,找出 spark 原始碼目錄,然後選取「Maven 專案」。 - 在匯入精靈中,將設定保留為預設值即可。不過,通常啟用「自動匯入 Maven 專案」會很有用,因為專案結構的變更會自動更新 IntelliJ 專案。
- 如 建立 Spark 中所述,某些建置組態需要啟用特定設定檔。可以在匯入精靈的「設定檔」畫面中啟用與上述
-P[設定檔名稱]相同的設定檔。例如,如果要針對支援 YARN 的 Hadoop 2.7 進行開發,請啟用yarn和hadoop-2.7設定檔。稍後可以從「檢視」功能表存取「Maven 專案」工具視窗,並展開「設定檔」區段,來變更這些選項。
其他提示
- 「重新建置專案」可能會在專案編譯第一次時失敗,因為不會自動產生產生原始碼檔案。請嘗試在「Maven 專案」工具視窗中按一下「為所有專案產生原始碼並更新資料夾」按鈕,以手動產生這些原始碼。
- 與 IntelliJ 綑綁的 Maven 版本可能不夠新,無法用於 Spark。如果發生這種情況,「為所有專案產生原始碼並更新資料夾」動作可能會在未顯示任何訊息的情況下失敗。請記得將專案的 Maven 主目錄 (
喜好設定 -> 建置、執行、部署 -> Maven -> Maven 主目錄) 重設為指向較新的 Maven 安裝。您也可以先使用build/mvn指令碼建置 Spark。如果指令碼無法找到夠新的 Maven 安裝,它會下載並安裝較新版本的 Maven 到build/apache-maven-<version>/資料夾。 - 部分模組有基於 Maven 設定檔的可插入來源目錄(例如,同時支援 Scala 2.11 和 2.10,或允許針對不同版本的 Hive 進行交叉建置)。在某些情況下,IntelliJ 無法正確偵測使用 maven-build-plugin 來新增來源目錄。在這些情況下,您可能需要明確新增來源位置才能編譯整個專案。如果是這樣,請開啟「專案設定」並選取「模組」。根據您選取的 Maven 設定檔,您可能需要將來源資料夾新增至下列模組
- spark-hive:新增 v0.13.1/src/main/scala
- spark-streaming-flume-sink:新增 target\scala-2.11\src_managed\main\compiled_avro
- spark-catalyst:新增 target\scala-2.11\src_managed\main
- 編譯可能會失敗,並出現「scalac:錯誤選項:-P:/home/jakub/.m2/repository/org/scalamacros/paradise_2.10.4/2.0.1/paradise_2.10.4-2.0.1.jar」等錯誤。如果是這樣,請前往「喜好設定」>「建置、執行、部署」>「Scala 編譯器」,並清除「其他編譯器選項」欄位。這樣應該就可以正常運作,不過當專案重新匯入時,選項會再次出現。如果您嘗試使用準引號建置任何專案(例如,sql),則需要將該 jar 設為編譯器外掛(就在「其他編譯器選項」的下方)。否則,您會看到類似這樣的錯誤
/Users/irashid/github/spark/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/codegen/CodeGenerator.scala Error:(147, 9) value q is not a member of StringContext Note: implicit class Evaluate2 is not applicable here because it comes after the application point and it lacks an explicit result type q""" ^
遠端偵錯 Spark
本部分將說明如何使用 IntelliJ 遠端偵錯 Spark。
設定遠端偵錯組態
依序按一下執行 > 編輯組態 > + > 遠端,以開啟預設的遠端組態範本: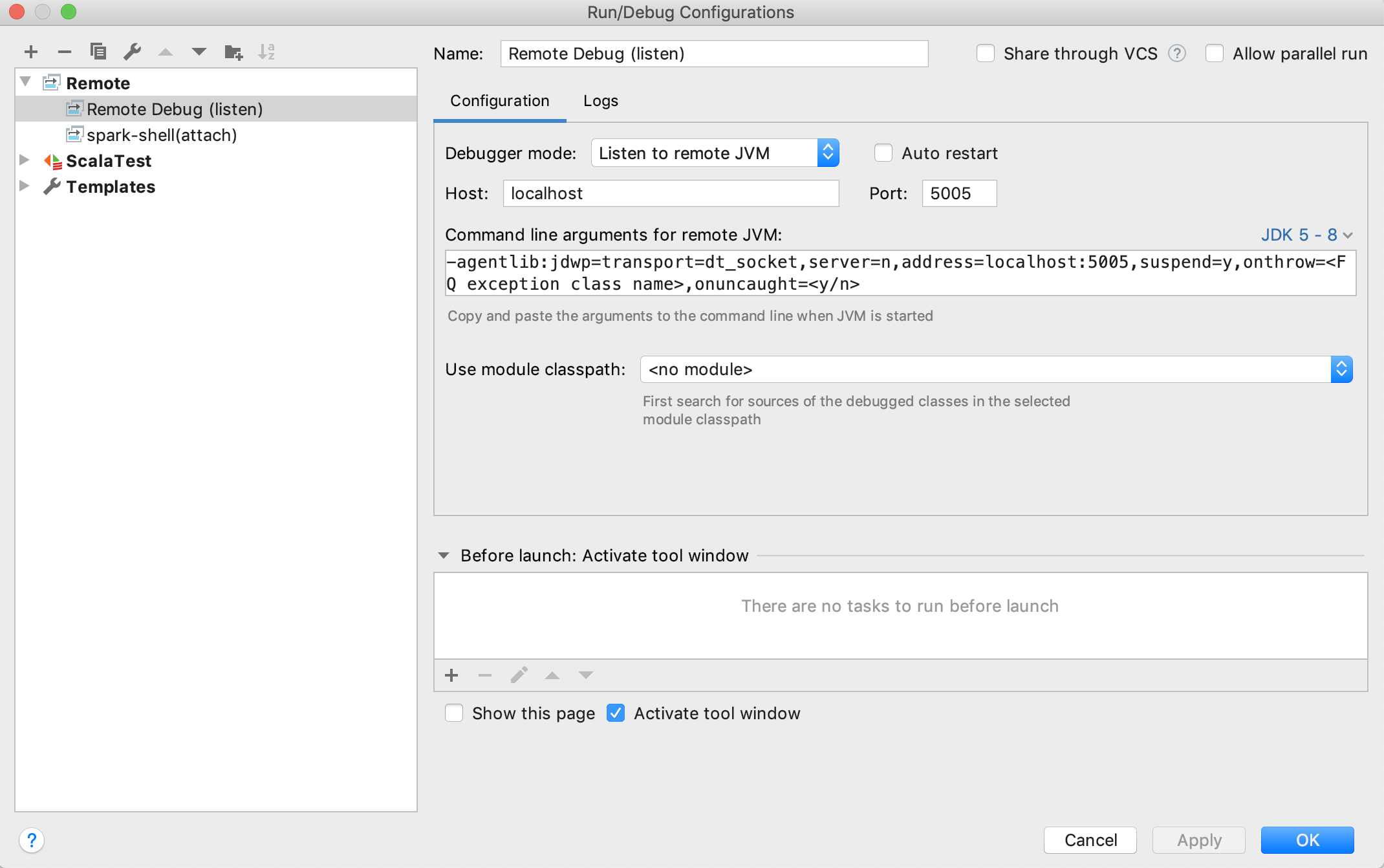
一般來說,預設值應該就夠用了。請務必選取傾聽遠端 JVM作為偵錯模式,並選取正確的 JDK 版本,以產生適當的遠端 JVM 的命令列引數。
完成組態並儲存後,您可以依序按一下執行 > 執行 > Your_Remote_Debug_Name > 偵錯,以開始遠端偵錯程序,並等待 SBT 主控台連線
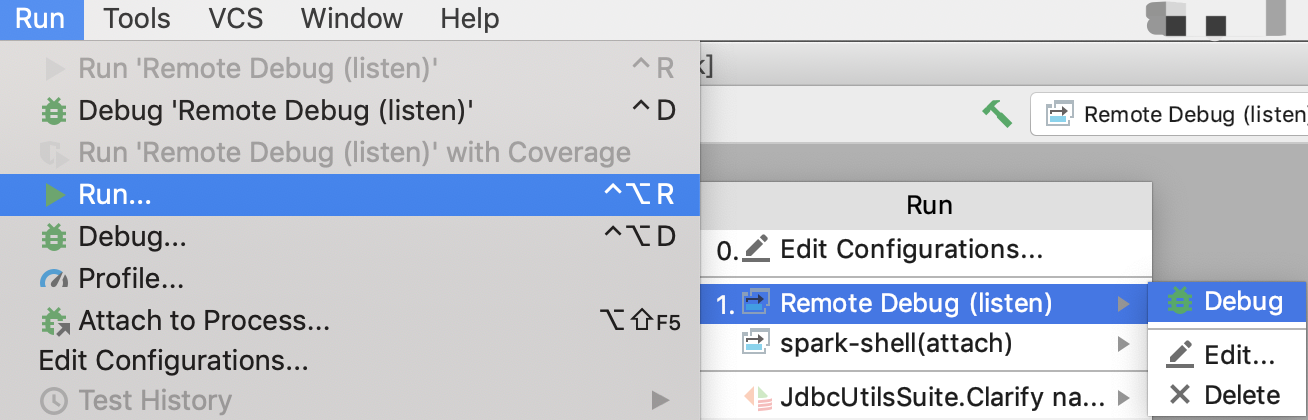
觸發遠端偵錯
一般來說,有 2 個步驟
- 使用上一步驟產生的遠端 JVM 的命令列引數設定 JVM 選項。
- 開始執行 Spark(SBT 測試、pyspark 測試、spark-shell 等)
以下是使用 SBT 單元測試觸發遠端偵錯的範例。
輸入 SBT 主控台
./build/sbt
切換到目標測試所在的位置,例如
sbt > project core
貼上遠端 JVM 的命令列引數
sbt > set javaOptions in Test += "-agentlib:jdwp=transport=dt_socket,server=n,suspend=n,address=localhost:5005"
使用 IntelliJ 設定中斷點,並使用 SBT 執行測試,例如
sbt > testOnly *SparkContextSuite -- -t "Only one SparkContext may be active at a time"
當您在 IntelliJ 主控台中看到「已連線至目標 VM,位址:『localhost:5005』,傳輸:『socket』」時,應該已成功連線至 IntelliJ。然後,您就可以在 IntelliJ 中開始偵錯,就像平常一樣。
若要結束遠端除錯模式(這樣就不必一直啟動遠端除錯器),請在專案中於 SBT 主控台中輸入「session clear」。
Eclipse
Eclipse 可用於開發和測試 Spark。已知下列組態可行
- Eclipse Juno
- Scala IDE 4.0
- Scala Test
最簡單的方法是從 Scala IDE 下載頁面下載 Scala IDE 軟體包。它已預先安裝 ScalaTest。或者,使用 Scala IDE 更新網站或 Eclipse Marketplace。
SBT 可以建立 Eclipse .project 和 .classpath 檔案。若要為每個 Spark 子專案建立這些檔案,請使用此命令
sbt/sbt eclipse
若要匯入特定專案,例如 spark-core,請選擇 檔案 | 匯入 | 現有專案 至工作區。請勿選擇「將專案複製到工作區」。
如果您想在 Scala 2.10 上開發,則需要為編譯 Spark 所使用的確切 Scala 版本組態 Scala 安裝。由於 Scala IDE 軟體包目前已將最新版本(2.10.5 和 2.11.8)組合在一起,因此您需要在 Eclipse 偏好設定 -> Scala -> 安裝 中新增一個,方法是指出 Scala 2.10.5 發行版的 lib/ 目錄。完成此動作後,請選取所有 Spark 專案並按一下滑鼠右鍵,選擇 Scala -> 設定 Scala 安裝 並指出 2.10.5 安裝。這應該會清除所有關於無效跨編譯函式庫的錯誤。現在應該會執行乾淨的建置。
ScalaTest 可以透過按一下滑鼠右鍵來源檔案並選擇 以身分執行 | Scala 測試 來執行單元測試。
如果發生 Java 記憶體錯誤,可能需要增加 Eclipse 安裝目錄中 eclipse.ini 的設定。視需要增加下列設定
--launcher.XXMaxPermSize
256M
夜間建置
Spark 會在每晚發布主控端和維護分支的 Maven 工件 SNAPSHOT 版本。若要連結到 SNAPSHOT,您需要將 ASF snapshot 儲存庫新增到您的建置中。請注意,SNAPSHOT 工件是暫時的,可能會變更或移除。若要使用這些工件,您必須在 https://repository.apache.org/snapshots/ 新增 ASF snapshot 儲存庫。
groupId: org.apache.spark
artifactId: spark-core_2.12
version: 3.0.0-SNAPSHOT
使用 YourKit 分析 Spark 應用程式
以下是使用 YourKit Java Profiler 分析 Spark 應用程式的說明。
在 Spark EC2 映像上
- 登入主控端節點後,請從 YourKit 下載頁面 下載適用於 Linux 的 YourKit Java Profiler。此檔案相當大(約 100 MB),而且 YourKit 下載網站有些慢,因此您可能會考慮鏡像化此檔案或將其包含在自訂 AMI 中。
- 將此檔案解壓縮到某個位置(在我們的案例中為
/root):unzip YourKit-JavaProfiler-2017.02-b66.zip - 使用 copy-dir 將已解壓縮的 YourKit 檔案複製到每個節點:
~/spark-ec2/copy-dir /root/YourKit-JavaProfiler-2017.02 - 透過編輯
~/spark/conf/spark-env.sh並新增下列行,組態 Spark JVM 以使用 YourKit 分析代理SPARK_DAEMON_JAVA_OPTS+=" -agentpath:/root/YourKit-JavaProfiler-2017.02/bin/linux-x86-64/libyjpagent.so=sampling" export SPARK_DAEMON_JAVA_OPTS SPARK_EXECUTOR_OPTS+=" -agentpath:/root/YourKit-JavaProfiler-2017.02/bin/linux-x86-64/libyjpagent.so=sampling" export SPARK_EXECUTOR_OPTS - 將更新後的組態複製到每個節點:
~/spark-ec2/copy-dir ~/spark/conf/spark-env.sh - 重新啟動 Spark 集群:
~/spark/bin/stop-all.sh和~/spark/bin/start-all.sh - 預設情況下,YourKit 分析器代理程式使用埠
10001-10010。若要將 YourKit 桌面應用程式連線到遠端分析器代理程式,您必須在集群的 EC2 安全群組中開啟這些埠。為此,請登入 AWS 管理主控台。前往 EC2 區段,並從頁面左側的網路與安全性區段中選取安全群組。找出與您的集群對應的安全群組;如果您啟動一個名為test_cluster的集群,則您會想要修改test_cluster-slaves和test_cluster-master安全群組的設定。對於每個群組,從清單中選取它,按一下入站標籤,並建立一個新的自訂 TCP 規則,開啟埠範圍10001-10010。最後,按一下套用規則變更。請務必對兩個安全群組都執行此操作。注意:預設情況下,spark-ec2會重複使用安全群組:如果您停止此集群並啟動另一個具有相同名稱的集群,您的安全群組設定將會重複使用。 - 在您的桌面上啟動 YourKit 分析器。
- 從歡迎畫面選取「連線到遠端應用程式…」,並輸入 Spark 主控或工作機器的位址,例如
ec2--.compute-1.amazonaws.com - YourKit 現在應已連線到遠端分析器代理程式。分析資訊可能需要幾分鐘才會出現。
請參閱完整的 YourKit 文件,以取得分析器代理程式 啟動選項 的完整清單。
在 Spark 單元測試中
透過 SBT 執行 Spark 測試時,將 javaOptions in Test += "-agentpath:/path/to/yjp" 加入 SparkBuild.scala,以啟動啟用 YourKit 分析器代理程式的測試。
檔案分析工具的平台特定路徑列於 YourKit 文件 中。
生成式工具使用
一般而言,ASF 允許使用生成式 AI 工具共同撰寫的貢獻。然而,在提交包含生成內容的修補程式時,有幾個事項需要考量。
最重要的是,您必須揭露此類工具的使用。此外,您有責任確保該工具的條款和條件與在開放原始碼專案中的使用相容,且包含的生成內容不會構成侵犯著作權的風險。
有關詳細資訊和發展,請參閱 ASF 生成式工具指南。
最新消息
- Spark 3.4.3 發布 (2024 年 4 月 18 日)
- Spark 3.5.1 發布 (2024 年 2 月 23 日)
- Spark 3.3.4 發布 (2023 年 12 月 16 日)
- Spark 3.4.2 發布 (2023 年 11 月 30 日)
