易於使用
可用於 Java、Scala、Python 和 R。
MLlib 符合 Spark 的 API,並與 Python 中的 NumPy(Spark 0.9 起)和 R 函式庫(Spark 1.5 起)互通。您可以使用任何 Hadoop 資料來源(例如 HDFS、HBase 或本地檔案),輕鬆插入 Hadoop 工作流程。
.load("hdfs://...")
model = KMeans(k=10).fit(data)
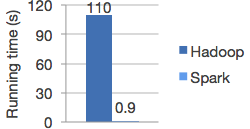
效能
高品質演算法,比 MapReduce 快 100 倍。
Spark 擅長反覆運算,讓 MLlib 能夠快速執行。同時,我們重視演算法效能:MLlib 包含利用反覆運算的高品質演算法,而且能產生比 MapReduce 有時使用的單次近似更好的結果。
到處執行
Spark 可在 Hadoop、Apache Mesos、Kubernetes、獨立或雲端上執行,針對不同的資料來源。
您可以使用 獨立叢集模式、EC2、Hadoop YARN、Mesos 或 Kubernetes 來執行 Spark。存取 HDFS、Apache Cassandra、Apache HBase、Apache Hive 和數百個其他資料來源中的資料。

演算法
MLlib 包含許多演算法和實用程式。
ML 演算法包括
- 分類:邏輯迴歸、樸素貝氏...
- 迴歸:廣義線性迴歸、生存迴歸...
- 決策樹、隨機森林和梯度提升樹
- 推薦:交替最小二乘法 (ALS)
- 分群:K 平均、高斯混合模型 (GMM)...
- 主題模型:潛在狄利克雷配置 (LDA)
- 頻繁項目集、關聯規則和順序模式探勘
ML 工作流程實用程式包括
- 特徵轉換:標準化、正規化、雜湊...
- ML 管線建置
- 模型評估和超參數調整
- ML 持久性:儲存和載入模型和管線
其他實用程式包括
- 分散式線性代數:奇異值分解、主成分分析...
- 統計:摘要統計、假設檢定...
參閱 MLlib 指南 以取得使用範例。
社群
MLlib 是作為 Apache Spark 專案的一部分開發的。因此,它會在每次 Spark 發行時進行測試和更新。
如果您對此函式庫有任何疑問,請在 Spark 郵件清單 中詢問。
MLlib 仍是一個快速成長的專案,並歡迎貢獻。如果您想提交演算法至 MLlib,請閱讀 如何貢獻 Spark 並寄送補丁給我們!
最新消息
- Spark 3.4.3 發行 (2024 年 4 月 18 日)
- Spark 3.5.1 發行 (2024 年 2 月 23 日)
- Spark 3.3.4 發行 (2023 年 12 月 16 日)
- Spark 3.4.2 發行 (2023 年 11 月 30 日)
